Project 5 / Face Detection with a Sliding Window
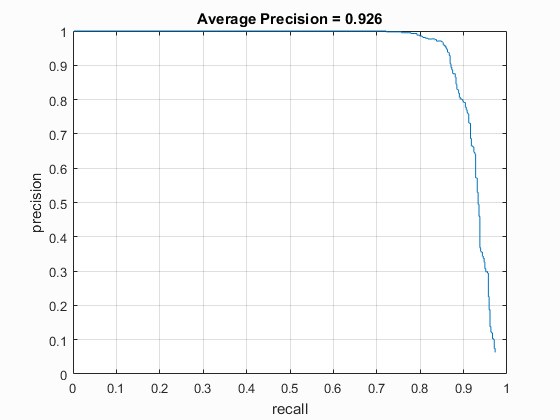
For my implementation, I was able to get up to about 93% accuracy using multiple scales and a HOG cell size of 3 pixels. Below is my precision recall curve showing an average precision of 92.6%. For my submission, I raised the HOG cell size back up to the default size of 6 pixels and the whole pipeline runs in about a minute. This reduced the average precision down to about 85% though.
Feature Training
Getting the positive features was fairly straightforward. Each 36x36 training image is converted to a HOG feature, reshaped into a vector, and then stored in the positive feature matrix. For the negative features, for each image, I cut out template_size patches (36x36) randomly from each image and then convert them to HOG features. Finally, a linear SVM is trained using the positive and negative features. I was able to obtain the best accuracy with a lamba of 0.00001. Increasing or decreasing the lambda by a factor of 10 didn't affect the accuracy too much, but I found it to drop off pretty significantly outside of that region. Together, this trained the following representation. If you squit, you can kind of make out a face with eyes and a nose.

Face Detection
For the actual face detection, I look at sliding patches of template_size over each image at multiple scales. I start with the image unscaled and add any detections to a dynamically growing array. After each pass, I resize the image by a scaling factor (I found 0.8 to work good in my testing) and repeat until the image is smaller in one of the dimensions than the template size. For each window, I caluclate the confidence and then add it only if the confidence is over a given threshold. Mine ended up being slightly negative, with -0.7 working well in my testing. Both of these values together struck a really good balance between precision, and not taking 20 minutes to run. Finally, after gathering all of potentially detected faces, I pass it through non-maximum supression to remove any duplicates. It was important to make sure that I ran the supression after all of the scales were computed, otherwise there were too many duplicates. Moving the non-maximum supression to after all of the scaled detection ended up increasing my precision by about 30-40%. It also caused the bounding boxes to match the ground truth sizes a lot better. Below are a few sample images showing detected faces.



|



|
All of these examples show very good recall, despite quite a few false positives. Images with large faces are still found correctly due to looking at faces with multiple scales. Even in images with differenct sized faces, the results are still good. Also, artificial faces shown on the card are matched correctly.