
Andrew Wood
School of Computer Science
The University of Birmingham
Edgbaston, Birmingham, B15 2TT UK
amw@cs.bham.ac.uk
There is, of course, merit in today's dominant mode of research, but we need to focus some software engineering research effort on more futuristic applications. By doing so, the software engineering community can again become a leading indicator for software systems that will be deployed in the coming ten years. Without this shift in perspective, the software engineering community is sending out the wrong message ---that our research is not intended to shape the landscape of future computing and is therefore of no interest to those who aspire to invent tomorrow's paradigms of interaction. Software engineering needs to become once again a leading indicator for the rapid pace of technology change.
Interest in ubiquitous computing has risen over the past few years [25,26,3] and one of the emerging research themes is context-aware computing [1]. In a computing environment with universal access to information anywhere and at any time, the end user will need leverage to help tame the deluge of technology. There is a lot of information surrounding the end user ---the user context--- that can be sensed and used to predict the kinds of information needed and the form in which that information should be delivered. From a software perspective, context-aware computing demands an infrastructure to allow intelligent mediation between software components, allowing them to act together in ways that might not have been predicted by the original designers [27].
The software engineering technique that shows much promise for context-aware computing is dynamic component integration. The remainder of this paper will demonstrate how dynamic integration techniques can support context-aware computing for future interactive environments.
Weiser admits that it is the applications themselves that make ubiquitous computing a viable research topic for computer science (and other disciplines) [26]. With that in mind, our research in ubiquitous computing has been strongly influenced by the applications which we have chosen to explore. One application domain we have investigated is personal information management. Today, there is a growing number of personal devices and applications, on and off the desktop, that allow us to keep track of our own personal repository of electronic information. Currently this information includes contact information, schedules, e-mail communications, but will extend to encompass a much greater portion of our everyday lives.
As users begin to rely more and more on electronic information, they will expect it to be available to them in a variety of different situations ---while in their office, at home, on the road. With the proliferation of mobile devices, it is possible to have access to personal information anywhere, but this is currently done at the expense of having to replicate similar information on a variety of devices. The promise of reliable, ubiquitous networking services should relieve the user of the bother of explicit replication or synchronization of data to the point where it is no longer a concern where information is located.
Universally accessible data is only part of the challenge, however. The relationship between data is important to the user, and very difficult to track as it becomes easier to acquire electronic information. Knowledge of the user's context ---what piece of information they are currently attending to, where they are located when they look at some information, the time of day, or the people around them--- can help to predict when relevant services might best be presented to a user. This requires a software infrastructure that can detect contextual information and then use it to offer advice to the user. It is this latter advice-giving feature that is the focus of this paper.
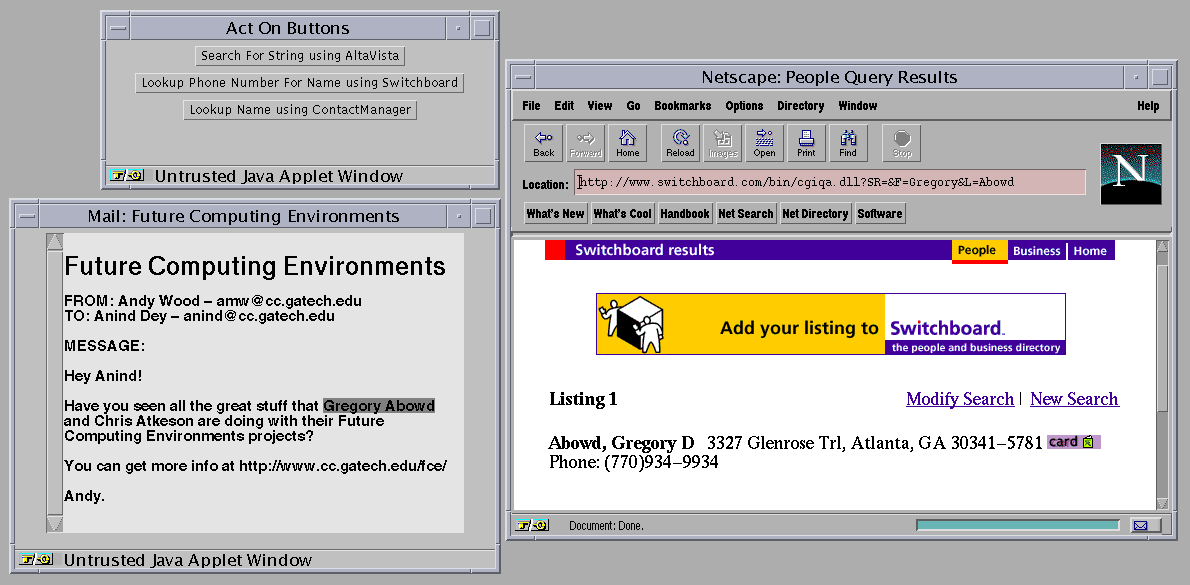
Figure 1. An illustration of a typical scenario using CyberDesk to
automatically integrate desktop, network and mobile data services.
Click on the screenshot to get an image with better resolution.
We emphasize some important features of this simple scenario. The services being accessed can reside anywhere ---on the user's desktop machine, on the Internet, or even on a mobile device such as a personal digital assistant (PDA) that is connected via wireless network [17]. Also, the user does not need to know what services are available, as relevant services are suggested automatically by the CyberDesk infrastructure and made available to the user based on the current context. The current context in this scenario is indicated explicitly by the user based on text that has been highlighted with a mouse, but we can also have more implicit context such as a user's position, trigger integrating suggestions.
A second issue is to provide an infrastructure for integrating software applications. Software applications often work on similar information types such as names, addresses, dates, and locations. Collections of applications are often designed to take advantage of the potential for integration via shared information. As an example, an electronic mail reader can be enhanced to automatically recognize Web addresses, allowing a reader to select a URL to automatically launch a Web browser on that location. Even more complex and useful integrating behavior is available in a number of commercial suites of applications (e.g. Microsoft Office 97, Lotus SmartSuite, WordPerfect Suite).
There are some limitations, however, to the current approaches for providing this integration that impact both the programmer and the user. From the programmer's perspective, the integrating behavior between applications is static. That is, the behavior must be identified and supported when the applications are built. The programmer has the impossible task of predicting all of the possible ways users will want a given application to work with all other applications. What results is a limited number of software applications that are made available in an integration suite.
From the user's perspective, integrating behavior is limited to the applications that are bound to the particular suite being used. Further integration is either impossible to obtain or must be implemented by the user (e.g., by cutting and pasting between application windows or by end-user macro programming). In addition, the integrating behavior has a strong dependence on the individual applications in the suite. If a user would like to substitute a comparable application for one in the suite (e.g. use a different contact manager, or word processor), she does so at the risk of losing all integrating behavior.
Given these software engineering considerations, our goal is to provide a more flexible framework for integrating software behavior based on knowledge of a user's context. We want our solution to work under the assumption of a networked and heterogeneous operating environment. We aim to reduce the programming burden in identifying and defining integrating behavior, while at the same time retaining as much user freedom in determining how integration is to occur.
A significant body of work in mobile computing takes advantage of the most significantly changing context of a mobile user ---location [2,12,24,6]. The initial ubiquitous computing research at PARC provided location-aware services for a handheld device called the PARCTab [24], and resulted in a generalized programming framework for describing location-aware objects [20]. Using informational context, such as what is shown on a user's graphical display (as depicted in the scenario of Section 2.1) has also been the subject of work done at Apple [5] and Intel [15]. This work is the most closely related work to our own and we will discuss it further in the next section on software integration.
Our underlying infrastructure allows dynamic integration of isolated services at run-time. Such mediation consists of two basic steps: registration of components and handling of events. This provides for the kind of flexible coordination or mediation between different components. We can compare our integration infrastructure with some other well-known systems, such as UNIX pipes, Field [18,19], Smalltalk-80 MVC [11], Common Lisp Object System (CLOS) [7]. UNIX pipes act as mediators that integrate UNIX programs. They are limited to reading and writing streams of data, stream outputs can only be input to one stream, and they use only a single event. Field (and its extension Forest) integrate UNIX applications that have events and methods which can be manipulated through a method interface. Similar to our work, Field uses centralized mediation and implicit registration, allowing greater runtime flexibility. However, it suffers from the use of special object components, creating inconsistencies. Smalltalk uses a general event mechanism like CyberDesk, but it merges relationships between components into the components themselves, limiting flexibility. CLOS uses wrappers to access data and methods within objects, as we do, but it limits the action a component can perform to a simple method call and return, thereby limiting its usefulness. Sullivan and Notkin [22,23] have developed a very flexible dynamic mediation system. However, their system allows only one-to-one relationships between components and requires explicit registration of event-action pairs.
We depend on the use of component software accessible across a network connection, similar to CORBA (Common Object Request Broker Architecture) [14], Microsoft's Common Object Model (COM) and Object Linking and Embedding (OLE) [13]. OpenStep [4] and others. A main dis tinction in our work is the requirement for a dynamic registry that records the presence of interacting components. At a higher semantic level, the agent research community has also spawned efforts to provide for integration of large-scale software systems [10]. Such efforts have been sponsored by the DARPA Knowledge Sharing Effort and have produced specification languages such as the Knowledge Query and Manipulation Language (KQML) and the Knowledge Interchange Format (KIF).
There are two systems in particular that provide functionality in the domain of personal information management similar to the scenario described in Section 2.1. They are Intel's Selection Recognition Agent [15] and Apple Research Lab's Data Detectors [5].
Intel's Selection Recognition Agent uses a fixed data type-action pair, allowing for only a static set of actions for each data type recognized. The actions performed by the agent are limited to launching an application. When a user selects data in an application, the agent attempts to convert the data to a particular type, and displays an icon representative of that type (e.g. a phone icon for a phone number). The user can view the available option by right-clicking on the icon with a mouse. For applications that do not ``reveal'' the data selected to the agent, the user must copy the selected data to an application that will reveal it.
Apple Data Detectors is another component architecture that supports automatic integration of tools. It works at the operating system level, using the selection mechanism and Apple Events that most Apple applications support. It allows the selection of a large area of text and recognizes all user-registered data types in that selection. Users view suggested actions in a pop-up menu by pressing a modifier key and the mouse button. It supports an arbitrary number of actions for each data type. When a data type is chosen, a service can collect related information and use it, but this collected information is not made available to other services.
The main limitations of the Intel and Apple work for context-aware computing is the inability to accept a very rich set of context input. These systems report support for only displayed information. We aim to support other forms of context such as time and position. Extensions to our initial infrastructure to support chaining and combining also provide much more powerful context-inferencing capabilities, as we will discuss.
The starting point of our Java implementation was an infrastructure called CAMEO, a C++ toolkit developed by Andy Wood [28] (For further information on CAMEO, see http://www.cs.bham.ac.uk/~amw/cameo.) The CAMEO infrastracture defines a component-based framework in which individual components can observe the activities of other components and manipulate their interfaces. A centralized service allows for dynamic registration of components and runtime support for querying the interfaces of registered components. Observation and manipulation of other components and the dynamic registry services of CAMEO were sufficient motivation for us to port to Java and take advantage of simpler cross-platform network access to a multitude of Web-based, mobile and desktop information services.
The run-time relationship between the components (not including the Registry) is depicted in Figure 2. The components are described in greater detail below.
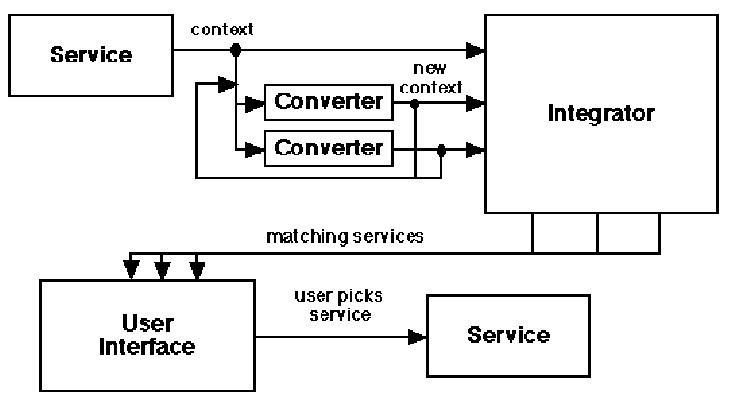
Figure 2. The run-time architecture of CyberDesk. Arrows indicate
the flow of information and control in the system..
Service wrappers are used to integrate existing services into CyberDesk. These wrappers adapt the interfaces of the existing services to conform with the CyberDesk registration and communication requirements. They make the functionality of the services accessible to other components, and provide methods for communicating with other components and registering their interfaces with the Registry.
Services not only provide functionality to the user, but they can also provide data to the system, as seen in the simple scenario. When users select data with a mouse in an application, that data is observed by interested components (a subsect of the type converters and the Integrator described below). The author of the service wrapper determines what information and functionality is made available to the CyberDesk system.
This announced data is the contextual information, as its origin is some user activity, such as selecting text with the mouse.
The type converters provide a separable context-inferencing engine with arbitrary power. As the conversion abilities of the converters improves, the ability of the system to make relevant service suggestions also improves. Therefore, the apparent intelligence of CyberDesk is also contained within the type converters. Since the type converters are represented as a collection of Java classes, it is a simple matter to boost the overall power of this context inference engine without impacting any of the functionality of the rest of the system.
As mentioned in the section on the Registry, some components are interested in the addition and removal of other components. Type converters are examples of this. Type converters monitor which services are added and removed from the system, so they can determine which components can provide data, and observe those components.
When components register or remove themselves from the Registry, the Integrator is notified. The Integrator uses this information to update its list of components to observe data from and to update its list of components that can act on various types of data. For example, when the Switchboard service is added to CyberDesk, it registers that it can perform a function on name information. The Registry notifies all components interested in the addition and removal of components: type converters and the Integrator. The Integrator contacts the Registry to determine the kind of interface the Switchboard service supports and finds out that it can act on name data. When name data enters the system, the Integrator makes the Switchboard service available to the user.
The user interface, like the other components, is completely interchangeable. If the provided user interface does not meet with the user's approval, it can be easily replaced by another user interface that better informs the user of the connection between his current context and suggestions for future actions based on that context.
A simple extension, chaining, decreases the level of complexity necessary to perform such actions. Chaining is the process of generating additional context for the purpose of increasing integrating behavior. Many services take one type of data and return another form of data through a graphical interface, such as a Web browser. Examples of these services are e-mail address lookups, phone number lookups, and mailing address lookups. By making simple modifications to the service wrappers, services can be made to behave like type converters, taking one form of context and returning another. The modifications to the CyberDesk system included parsing the data encoded in the graphical interface to obtain the new data and supplementing the registration information of services to be more like that of type converters. Now services can suggest actions directly related to the user's context and actions indirectly related to the user's context, reducing the effort required by the user to find these services.
As an example, assume a user is reading an appointment in her scheduler and selects the name of the person she is supposed to be meeting (see Figure 3. As an experienced user, she expects to be presented with a list of all possible services that can use a name: search for a phone number, mailing address, look up in the contact manager, search name on the Web, etc. Chaining now adds powerful suggestions. The WhoWhere Web service takes a name as input and returns a Web browser showing a list of possible e-mail addresses corresponding to that name. By making the assumption that the first e-mail address returned in the list is the correct one, we can now use this service to convert the name to an e-mail address. The service now creates related e-mail address data, and the user is supplied with all possible suggestions for a string, a name, and an e-mail address.
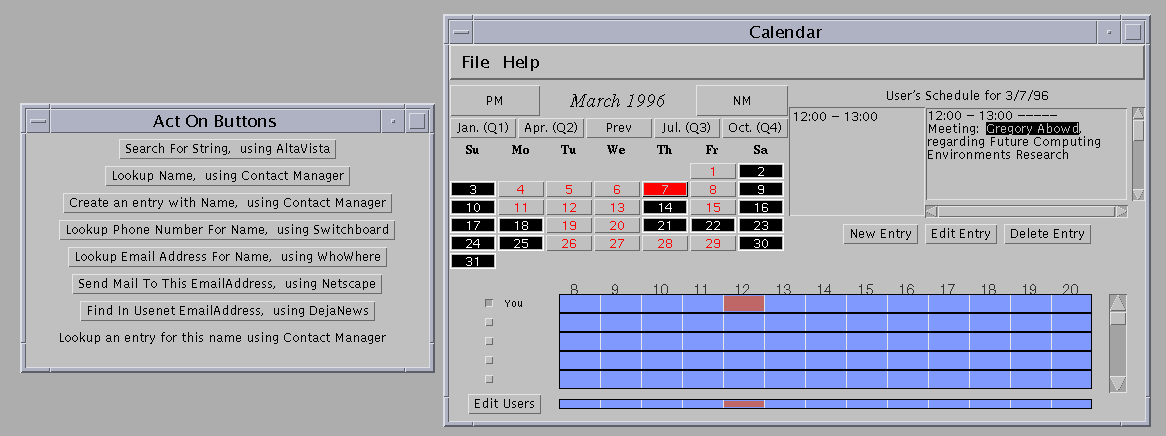
Figure 3. An example of the chaining extension to CyberDesk.
Click on the screenshot to get an image with better resolution.
When newly converted data is observed, the combining ability takes the newly converted data and adds it to the original data creating a more complex data object. This new data triggers more powerful actions. Using the previous example of a user reading an appointment in her scheduler, the user selects a name, and a chaining service like Four11 is used to obtain a mailing address for this name. Using combining, a data object containing both the name and the mailing address may now be used as input to a phone number lookup service like Switchboard. Switchboard can find phone numbers when given simply a name as input, but it can perform a more accurate search when it is provided with both a name and a mailing address.
Most services will perform better when provided with pertinent, additional context to work with. CyberDesk determines how to bind data together based on the data it currently has (the sum total of the current user context) and on the services available. It will offer a suggestion to use Switchboard with just a name as input when only name information is available, but will suggest Switchboard with a name and a mailing address if both pieces of information are available.
In a more complete example of combining, the user selects the name of a person she is meeting tomorrow. Immediately, she is offered suggestions of actions that she can perform with the selected string and name. As the chaining applications return their data, this suggested list of actions is augmented with actions that can use an e-mail address (via WhoWhere), phone numbers and mailing addresses (via Switchboard) and URLs (via AltaVista). At the same time, the Integrator is dynamically binding these individual pieces of data for services that benefit from multiple data inputs. The user chooses to create a new entry in the contact manager. This results in a rich entry, containing the original name she selected, an e-mail address, a URL, a phone number, and a mailing address.
We are developing a mobile application that takes advantage of this extension. A sample scenario follows. At noon, a user enters his kitchen and walks up to a mobile computing tablet hanging on his refrigerator. A recognition system determine the identity of the user and his location in front of the refrigerator. The tablet displays a list of suggestions to the user: show a list of items in the refrigerator, search for a recipe that can be made with the items in the refrigerator, or display the latest family pictures. The user picks up the display and moves into the living room and sits on the couch. The positioning system recognizes that the user and tablet have moved into the living room and the system offers the following list of suggestions: view today's news, read personal e-mail messages, or browse an electronic journal. A little later, a business partner drops by and the user moves to his office with his partner. The system recognizes the partner and determines the current location of the display and user. The display now suggests looking up the partner's contact information, viewing business-related newsgroups, viewing notes from the last meeting attended by both the user and the partner.
As can be seen in this scenario, the suggestions offered by the system are tailored to the current location and identification of the people using it. The services suggested to the user are limited by the context of the user and his surrounding environment, thus reducing the potential problem of suggestion overload.