
![]()
We live in a world where fully featured mobile devices (PDA, etc) are gaining wider acceptance and usage. More and more people are replacing their day planners with Newtons, Pilots, etc. Now that the data is electronically manageable, there should be a method for easily accessing and working with the data stored on the mobile device from the user's desktop machine (where they are likely to spend a lot of their time) or from other mobile devices.
LlamaShare is being developed by Mike Pinkerton under the guidance of Dr. Gregory Abowd for the Future Computing Environments (FCE) group at Georgia Tech.
There are two goals of this project.
This work will be developed into a Masters Thesis, to be completed by June, 1997 (or bust!).
Anyone who can guess where the name came from gets a cookie (it's not quite as obvious as you may think). Even if you're wrong, you'll be added to my guess list.
Let me give an example to show why this is useful, and how one application of LlamaShare works. Let's say I'm trying to write up directions for a visiting faculty member showing how to get to Georgia Tech. This is a common task for which people use their computers, especially around here. To be useful, the document should include:
Using today's software (eg, MS Word), the above would be very difficult (though not impossible) to accomplish. However, OpenDoc (a component architecture available for all major platforms) provides a perfect basis for adding arbitrary content to a document. If the document is an OpenDoc container (such as NisusWriter, ClarisWorks, or WAV), you can easily embed drawings, jpeg's, or tables anywhere within the document using drag and drop, without the requirement that the container be programmed to accept each specific data type.
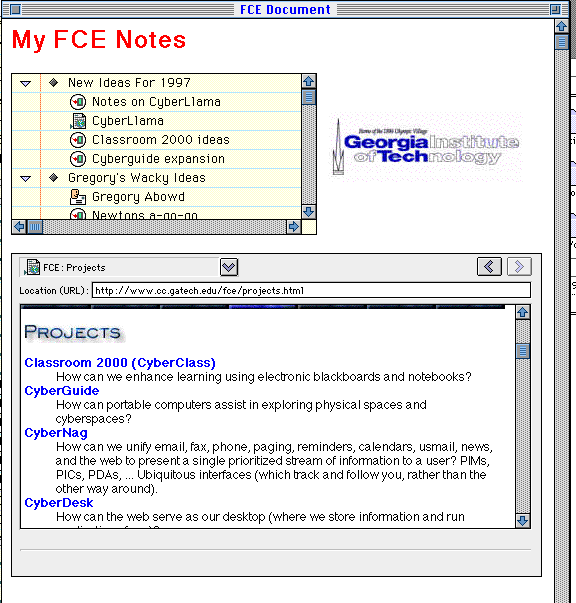
An example document created with OpenDoc
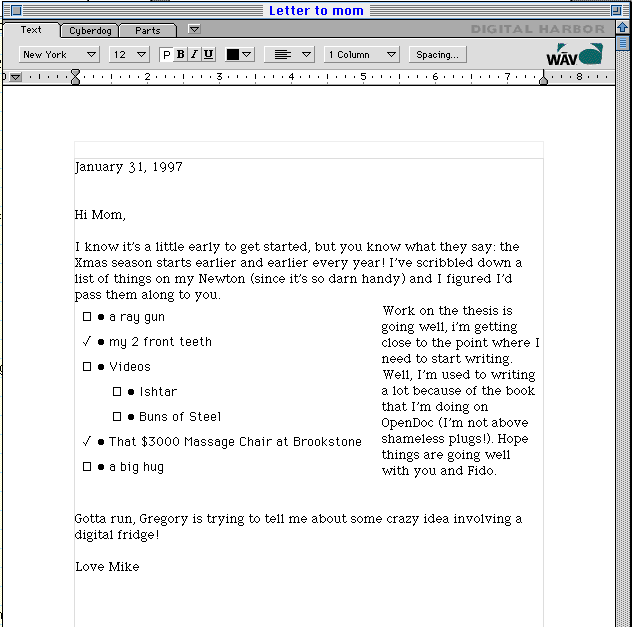
I created the above document simply by dragging and dropping OpenDoc objects (called parts) into it. No coding (even HTML coding) was necessary. All that is left is the map, which I happen to have drawn on my Newton this morning before I came to school.
From a user's perspective, the question is obvious: "How do I get it off of my Newton and into my document?"
A lot of effort has gone into the "synchronization" approach to integrating mobile devices into the desktop world. When the user wants to access any data on their mobile device, they must explicitly go to a special "docking" program which will download the information from the mobile unit to the computer, hopefully in a format which desktop applications can understand. This is the approach taken by the US Robotics Pilot and the Newton Connection Utilities from Apple Computer.
Using this approach, a typical user interaction goes like this:
This is a very long and complicated process, which distracts the user from their current task and leads them on a wild goose chase through multiple applications and tedious steps. Furthermore, once they reach the final step, they may not even be able to integrate the data because it is not in a format the application understands.
One goal of my work is to streamline this process to as few steps as possible, leveraging skills and techniques users are currently familiar with when working with desktop systems (drag and drop, etc).
The final goal would be to shrink the above tedium down to the following:
That's it! The data is in-place and ready to use. No explicit user integration is necessary because the desktop architecture (OpenDoc) already supports embedding arbitrary content inside of a document.
The finished document with embedded Newton drawing
While this is just one simple example of one particular application, it clearly demonstrates the need to simplify access to information stored on mobile devices. LlamaShare breaks down the barriers between users and their data.
An important question to address is how the user will address and organize the mobile data once they have access to it. We currently have two desktop applications that take very different approaches in their solutions, both of which are fully and equally supported by the infrastructure:
|
CyberLlama OpenDoc part |
Illustrated above, the CyberLlama OpenDoc part integrates with Cyberdog from Apple Computer. Cyberdog is a collection of OpenDoc parts for accessing remote/Internet data to which we have extended to include a part to access Newton data. |
|---|---|
|
| |
|
Cyberdesk & JavaLlama |
We have integrated JavaLlama (the Java front-end to the architecture) with CyberDesk, a separate research project for allowing users to access information through simple "agents" which search multiple information spaces (the Internet, local data, etc) based on context. |
When people use thier mobile device as a day planner, they keep names, addresses, notes and to-do lists on their mobile unit, not necessarily on their desktop machine. What is the point of redundantly keeping two copies of this information which always require synchronization? This information should just be accessable directly from the mobile device while the user is at their desk. This begs the question, "Where does a user look for mobile (or even remote) data?"
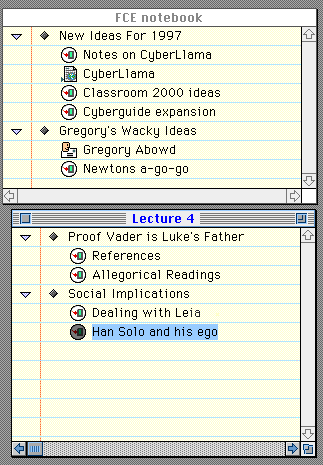
We can use OpenDoc/Cyberdog to solve this problem. Cyberdog allows users to store Internet URLs (called CyberItems) in notebooks as well as in buttons that load the appropriate content when clicked on. Any transport type (html, ftp, gopher, telnet, appleTalk, etc) is acceptable. Since Cyberdog is based upon OpenDoc, it is possible to add new transport types, which is what we have done for the Newton (notice the "My Xmas List" icon in the notebook below). The notebook metaphor provides a perfect opportunity to integrate mobile data into a location where users are already accustomed to looking for remote data.
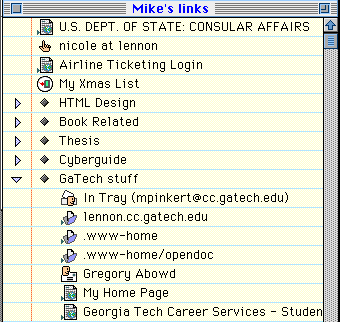
Now, any mobile data can be referenced by its CyberItem's icon (re-christened, obviously, a LlamaItem) which uniquely identifies a piece of data on a particular mobile device (such as a note or a name) just as a real URL unambiguously references a document on the specified server. These URLs can be stored as CyberItems in a Cyberdog notebook or in a CyberButton, and when they are opened, the appropriate data will be downloaded from the remote device an displayed in an editor on the screen. The data can be edited in-place and any changes are sent back to the mobile device where they are saved.
Integrating this data into documents is now just as simple as dragging the CyberItem into a document. OpenDoc will embed this item into the document and Cyberdog will then download the mobile information straight from the Newton. The user doesn't have to know anything about how the information gets transferred or where it actually resides (it could be on a Newton in someone else's office!).
The important thing to realize is that Cyberdog users are already accustomed to looking in notebooks for remote data. Up until now, that remote data was either always Internet data or data on an AppleTalk connected desktop machine. Now, we are adding mobile device data but the metaphor and interaction model remains constant. Users perform the same sequence of steps to acess and integrate data from mobile devices as they do with the Internet.
Applications: (By the by, the screenshots you see below are all real. This stuff actually works).
While CyberLlama provides a concrete, visible object to represent the data on a mobile device, CyberDesk takes the approach that information is distributed throughout a rather nebulous information space and can be retreived at any moment depending on the context in which the user is currently working. Judging from the actions that the user performs, they have access to information relevant to the current task which can be located on a variety of sources such as the Internet or a mobile device.
Describing the implementation and architecture of CyberDesk is beyond the scope of this web page. The CyberDesk project page and technical note are two places to find such information.
So where does LlamaShare fit into this research? In parallel with CyberLlama, I have also developed a Java package (a collection of objects which can be dropped into any client application or applet) which serves as a front-end interface to the LlamaShare server. The package, called JavaLlama, can be dropped in any Java applet or application and provides the ability to retrieve, manipulate, and display a wide range of Newton information. Since CyberDesk was written in Java, I was able to extend CyberDesk with a collection of services which gave users access to information stored in the Names and Notes soups.
Of equal importance to its contribution to CyberDesk, JavaLlama also demonstrates that LlamaShare provides access to mobile data to programs running on any platform, not just the MacOS or Windows, and written in any language, not just C or C++. Now applications can be written to access mobile information in the environment that best suits the developer, whether it is C++ on the MacOS (Cyberdog) or Java on a UNIX box (CyberDesk).
The following shot shows the CyberDesk "Act On" buttons, a floating palette of actions which show the services currently available for the user's selection. In this case, the I selected a name in an email message so CyberDesk presents me with the option to search for this name on the Newton (in both Notes and in Names) in addition to the standard searches of various locations on the internet.
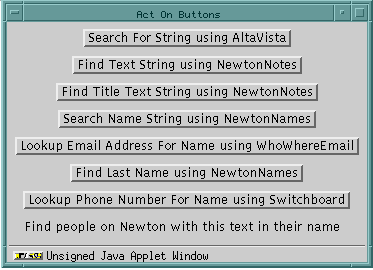
Another screen-shot of CyberDesk/JavaLlama illustrates retrieving all the notes that contain the text "teeth" on my Newton including the display of the relevant notes on the desktop. The user could just have easily searched the Internet for this information.
Notice that the JavaLlama service extensions integrate seamlessly with the other CyberDesk services, providing the ability to locate information regardless of its location or representation. As with the CyberLlama application above, the user uses the same interaction techniques to locate mobile information as when they want to locate local or Internet data. The only difference is that the data is now on a mobile device, but totally unlike the synchronization model, the user never needs to be concerned with the details of fetching it.
Applications: (again, these are all real screen shots. No fakes here, folks!)
The previous examples illustrated only a handful of the goals, namely the ones dealing with accessing mobile data on a desktop machine. However, the architecture also provides the ability for multiple mobile devices to collaborate and aggregate information. This next example provides an application of both of those features.
The CyberGuide project, also from the FCE group, uses mobile devices as hand-held tour guides. Using a positioning system (IR for indoors, GPS for outdoors), users can walk around an area and get not only where they currently are in the exhibit space, but information about each of the exhibits. Currently, all of the exhibit data and the maps must be manually loaded into each device. When the environment changes (which is common for demos, where a demo will move from one machine to another), each unit must be updated (again, manually) to contain the new information.
One major goal is to allow the mobile devices to dynamically load the information from the network, rather than having to store it all locally. That way, when the environment changes, every one of the mobile devices will have the up-to-date information instantly.
In addition to loading from the network, the mobile devices should be able to store new information collected from the device back to the network so that all other devices in the environment will have access to it. Imagine being able to add a new point of interest and then having everyone else instantly being aware of the new data point. Taking this one step further, user data, such as ratings from 1 to 10, could be aggregated into a global average that changes over time.
Finally comes collaboration. Each unit should be aware of the locations of the other units as well and be able to display them so that the person walking around with the device will know where everyone else is, or where to find important people (members of their group, human guides, security, etc).
Applications: (sorry folks, these don't exist yet)
The key piece in the infrastructure comprising LlamaShare is the LlamaServer which currently runs on a MacOS box. The LlamaServer acts basically like a glorified router, bridging the world of the desktop network (TCP/IP) to the network of mobile devices (currently AppleTalk).
The key features of the LlamaServer are:
Here is an illustration of the server architecture:
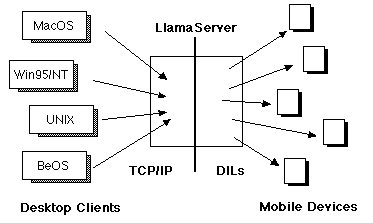
LlamaServer uses the Newton Desktop Integration Libraries (DILs) from Apple Computer to access information off of each Newton. The DILs provide low (byte at a time) and high level (frame at a time) communications between the server and a networked Newton allowing the server to talk to a Newton through a pipe (similiar to a UNIX stream). Since the DIL libraries are only available on MacOS and Windows for C and C++, we were limited on which platforms and in which languages we could implement our server (otherwise we would have certainly picked Java!).
When a desktop application (or applet) wants to access information off of a particular Newton (or some information about all of them), it opens a regular TCP/IP connection to the LlamaServer. It then sends a command (described in the table below) to the server asking for a particular kind of information. Our server then figures out which Newton contains the desired information and sends its own request over the DIL pipe which was opened when the Newton connected to the environment.
On the Newton side, a mini-server is waiting to respond to requests from the LlamaServer. It searches the Newton for the requested piece (or pieces) of information and returns the appropriate frames to LlamaServer , where they received using the higher level DIL functions. The Newton then waits for an acknowledgement of the frame from the server before sending the next one.
Back in the LlamaServer, we now have the task of sending this frame (represented in C as an unstructure tree of linked lists) over the Internet to the waiting desktop client. This process, called flattening, transforms the tree into a byte stream capable of being transmitted over TCP/IP. The client is in charge of performing the reverse operation (inflating) on its end of the TCP socket. After the server has sent a frame to the client, it ack's the Newton and waits for the next frame. Once all frames are sent, the server sends an "all done" message to the client to let it know nothing else is expected.
Here's an overview of the lock-step communication process described above:
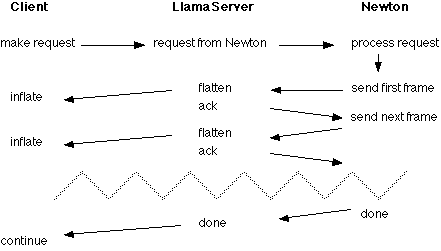
Since the server is fully threaded, it can handle multiple requests from desktop clients for information off of multiple mobile devices simultaneously. However, there is a limitation that only one desktop client can make a request for a particular Newton at a time; the others must wait until the request is completed before they can access the same information. This is because there is only one pipe between LlavaServer and the Newton, and multiplexing this pipe (and the mini-server on the Newton side) to handle multiple simultaneous requests would be much too difficult.
Here's a list of the commands that LlamaServer currently supports:
|
NEWT |
Returns a listing of the names of all Newtons registered to this server |
|
LIST |
Returns a list of all soups on a given Newton |
|
SOUP |
Retuns all entries in a given soup on a given Newton |
|
ENTR |
Returns a particular entry in a given soup on a given Newton |
|
FIND |
Searches through a soup on a given Newton returning all entries which contain the given text. |
While the above process makes it appear that Newtons might just serve as passive information repositories, this is far from the case. Each Newton can also be an active member in the environment and make its own requests for information from the LlamaServer. Applications can make use of the LlamaServer to request information from other Newtons in the environment.
The information from each Newton is collected into a "global soup." A global soup is similiar to a regular soup on a Newton except that it contains data from a collection of Newtons at the server. This soup can be queried to get information from any other Newton in the environment.
This portion is not completely implemented, and remains the only portion of LlamaServer that is unfinished. I'd estimate that we're about 40% completed with this segment.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}