
This report summaries the work done on the primatech project as of June 1999. The following people are involved with the project:
Chantek will be the first primate with language ability to be on public display at any zoo, and with Primatech visitors can learn about Chantek and experience what it is like to talk with him. In addition to supporting interaction and communication with Chantek, Primatech will introduce zoo visitors to sign language and perhaps teach them a few signs.
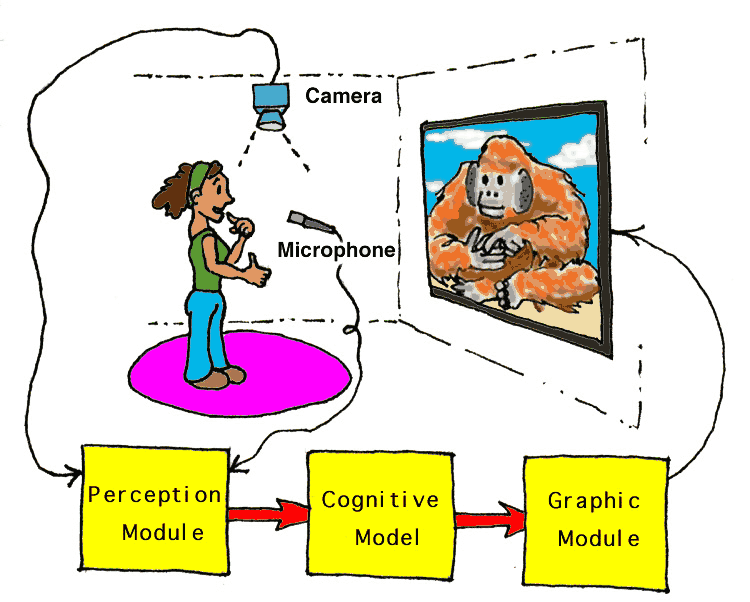
This is how the planned installation would work. The user, a zoo visitor, talks or signs a question or statement. The perception module interprets what the user is saying and turns it into text. This text is fed to the cognitive model, which generates an appropriate response. The cognitive model ouputs text to the graphic module, which generates an image of Chantek signing that response.
This document briefly describes the progress made on the Primatech project for the 98-99 school year.
The project is broken up into three modules: The artificial intelligence (AI), the perception module, and the graphics module. I will review the progress on the graphics and perception first; as the AI discussion is much more lengthy.
We did not build a model for two reasons: No one on the team was particularly talented at building 3d-graphic models, and we estimated that doing this, even without the learning curve, would take an unacceptable amount of time. The virtual gorilla models were very simple and according to Don Allison, not well suited for sign language. After talking to Gabe, Jessica and Don, and looking at numerous 3d models for sale, a gorilla model model was chosen. The only available oranguatan model was of a female, and the gorilla frankly looked more like Chantek. Jessica bought the model for us. It is broken up into pieces, though not necessarily the pieces we want. It had no skeleton.

In Spring 1999 I talked with some grad students in Jessica's lab and made a plan to get a skeleton for the gorilla and animate it. Tim made great progress spring 1999. He made a skeleton with the same dimensions as the gorilla and connected the parts appropriately. He animated several signs. The next steps are to connect the gorilla pieces to the skeleton and write a C++ program using inventor to animate the signs taking a stream of text as input.

Tim Keenan's stick figure
I had the opportunity to spend some time with Dr. Lyn Miles, some of her students, and Chantek. I got to see firsthand what he is like, and what kinds of things he signs.
To get an idea of what kinds of questions people would ask Chantek (and presumably an installation) I asked Tara Stoinski to ask zoo visitors what they would like to ask him.
The data received follows:
Husbandry related questions: 1. What do you like to eat? (5 people asked) 2. What do you like to do? (3) 3. Are you bored? (3) 4. What is it like to have fur? (1) 5. Do you like the animals that you live with? (1) 6. What is it like to live in a cage? (1) 7. Do you mind people staring at you all the time? (1) 8. Do you have a favorite keeper? (1) Abstract questions: 1. Are you happy? (7) 2. What do you want that you don't have? (4) 3. Do you want to go back to the wild? (2) 4. Tell me about evolution (1)Starting about a year ago I got very interested in general architectures for intelligence. I had been to the ACT-R summer school, and was involved with a research project in Ashok Goel's lab that was proposing an AI architecture as a cognitive architecture. In general I think cognitive architectures are great, there should be more, and more people should use them. However there are a few things that I found unsatisfying about architectures like Soar and ACT-R. Among them were 1) problems modeling language understanding, 2) a mapping to the brain, and 3) an unrealistic goal structure. While attending the AI cognitive science conferences I put the things I was learning into an architecture framework. I continued doing this for the better part of the fall quarter. I learned a great deal about the brain. The idea was that I wanted to make a simple cognitive architecture and model the primatech project in it. Near the end of the quarter, however, I realized that this goal was much too ambitious, particularly with regards to having a mapping to the brain-- there is just too much you need to know to contribute anything sensible. I did learn that the brain is surprisingly underconstraining, which is not what I expected. Turns out you can model all kinds of circuits, gates, anything you like, with neurons, and we don't know enough about the structure of the brain at that level to say that they can't exist (Shepard 1990). Seems like you could run lisp on a brain-like structure if you needed to. So when people make neural net models of cognition, you cannot critisize those models for being more powerful than the brain. The brain can do all of that and much much more. Trying to say anything interesting about the brain will take more time and education than I can afford to give at this point of my career. I had to backpedal and kind of start over, but some of the ideas I generated in this phase were used in subsequent modeling. Also I still have a notebook full of architecture ideas that I will go back to later in my career when I get into architectures again.
I switched gears and decided to attempt to model Chantek in ACT-R. Why? Because I have more faith in ACT-R as a cognitive model than any other architecture, particularly in terms of low-level cognition, which is what I wanted to try to model it with. Also I am very familiar with ACT-R and associate with a community of people who also use it.
However the thinking I had done about a new architecture facilitated new ideas about how modeling should be done, even in ACT-R. I will describe these changes in the description of the first model.
A typical ACT-R model might represent a concept this way:
(banana ISA fruit color yellow) (yellow ISA color)Instead of doing it like this, I split each word into three seperate chunks in memory: The concept, the word, and the sign. Because one can know a concept without knowing a word for it, one can recognize a sign but not know what it means, and one can understand a word without being able to generate it.
In addition I did not like the special ISA slot. It connects a chunk to its superclass, but some things have multiple superclasses associated with it (e.g. a dog is both a mammal and a pet.) I used the ISA slot provided in ACT-R to indicate what the thing in the head was (a concept, word, sign, etc.).
(cup-concept ISA concept word cup-word sign cup-sign r1 drink-concept) (cup-sign ISA sign meaning cup-concept) (cup-word ISA sign meaning cup-concept)Note that in the concept chunk there is a slot called "r1." This is a relevence link. There could be several relevence links for every concept linking related concepts. The relevence links are unlabeled so that the model is even simpler. How well can it do when relevent concepts are linked up without even labels on the links?
The concepts were linked using WordNet, which is an online dictionary I looked up every word in Chantek's vocabulary on wordnet, and if one of Chantek's words was in a word's definition, then a link between those two words were made. So in the above example, the word "drink" was in the definition of cup, so cup in related to drink.
The model worked like this: An input question was presented to the model. This caused spreading activation to occur (this is built into ACT-R). Then the system outputs whatever concept is most active. The most activated concept was retrieved, whatever it might be. A cooresponding sign was found and that sign was output. There were two productions that could fire: both retrieved a word and output it. One kept the goal to talk on the stack and the other popped the goal. When the goal stayed on the stack the system would continue to output signs. The average utterance length (of 100 trials) was 2.16, with a range of 1-8. This is close to the average utterance length of Chantek.
The results were not very impressive. Only 20% of the words in the vocabulary were linked. Few of the words in the input sentences were in the vocabulary, and the words returned were always in the input. This is in part due to the nature of the definitions in WordNet. The definition of Banana, for example, is "any of several tropical and subtropical treelike herbs of the genus Musa having a terminal crown of large entire leaves and usually bearing hanging clusters of elongated fruits." Needless to say, this definition has little to do with Chantek's conception of a banana. Also, it is pretty clear that 150 words does not get you very far. It sounds like a lot, but there really is not much you can do with it.
In conclusion, the definitions of Wordnet were too dictionary like, where what I needed were more like memory-associations. Also, 150 words is just not enough; this is a problem with all the models in this paper.
The same problem happens with the relevence link slots. There is a cap on the number of slots-- that is, the number of things the concept can be relevent to (r1, r2, r3...).
These two problems were solved in different ways. I broke up the representation of words in the input sentence into a linked list. The following represents the sentence "What do you like to eat?"
(goal-1-1 ISA goal-talk sentence-id 1 word what-word next-word goal-1-2) (goal-1-2 ISA goal-talk sentence-id 1 word do-word next-word goal-1-3) (goal-1-3 ISA goal-talk sentence-id 1 word you-word next-word goal-1-4) (goal-1-4 ISA goal-talk sentence-id 1 word like-word next-word goal-1-5) (goal-1-5 ISA goal-talk sentence-id 1 word to-word next-word goal-1-6) (goal-1-6 ISA goal-talk sentence-id 1 word eat-word next-word goal-1-7) (goal-1-7 ISA goal-talk sentence-id 1 word unknown next-word unknown)Version two included the following desires: food, drink, sex, freedom, and stimulation. ACT-R has a goal structure but no way to express desires that are always around but no specifically acted upon all the time.
Instead of linking concepts with relevence links, links were made from the concepts to the desires they satisfied, if any. Some concepts satisfy more than one desire, however, so the same problem with relevence links mentioned above would come up with desire satisfaction here as well. To solve the problem relations were explicitly represented. To maintain consistency, the way a sign or word means a concept was done in the same way. Relationships between concepts were chunks in themselves. See the examples below. "Relation2" is a chunktype for relations between two concepts. Each represents what the concepts are and the relation between them.
(satisfies-relation
ISA relation)
(meaning-relation
ISA relation)
(screwdriver-word-meaning
ISA relation2
relation meaning-relation
first screwdriver-word
second screwdriver-concept)
(dog-isa-animal
ISA relation2
relation subclass-relation
first dog-concept
second animal-concept)
Since the ISA slot is being used for what the chunk is for the mind,
rather than how the referent in the world is classified, an explicit
subclass-relation chunk is required. See the chunk dog-isa-animal
above for an example. Thus relations between concepts have one
consistent representation. Theoretically this means that relations, like any other chunks, can spread activation and be primed. The control was fairly simple. The model looked through the words in input one by one, and if a word was encountered that satisfied a desire, a goal was pushed to express that concept. The corresponding sign was retrieved and output.
This model is a clear improvement over the first. Chantek is oriented toward thing in his environment (Miles, personal communication), and this model responds rather appropriately when offered something it desies. Linguistically, though, it is incapable of doing very much. The third model got into more complexity linguistically.
However even this understander went beyond the published data to some extent. There is no evidence in the literature that Chantek has any grammatical ability at all. Certainly, when talking to him, he appears to. Once when I was watching him Dr. Lyn Miles asked Chantek to put his blanket in his bed, which he did. But note that grammar isn't really necessary to understand this sentence-- if I give you the words "put," "blanket" and "bed" you can probably figure out that you put the blanket on the bed rather than putting the bed on the blanket-- the bed is immobile! On the positive side, there is no evidence that he does not have grammar either. But since most apes do not have grammar abilities, we must assume from the lack of evidence in either direction that Chantek does not posess it.
There are also productions there to interpret the words that have been parsed. These can fire at any time after the word is in the grammar. What is does is replace the word with the meaning. So banana-word gets replaced with banana-concept (if and only if there is a connection to a concept from that word in the model's memory.)
Once the sentence is interpreted, the model attempts to verify the sentence. It checks the memory for a fact that has the same subject, verb, and object. If a match is not found, the model does nothing. If a match is found, a goal is pushed to express the verb-concept. An appropriate sign is found and output. The verb is output because the word "yes" is not in Chantek's published vocabulary. I got the idea from Chinese, where the verb is returned in place of yes.
Several interesting cognitive ideas were generated that are applicable not only to ape cognition but human cognition as well. I will summarize a few of them:
representation of input sentences: Most input for ACT-R models are in the form of slots in a goal. This is unsatisfactory for language input because it limits the size of the sentence or makes for extraordinarily large goal chunks. The solution offered in this work is to make a sort of linked list of the input words that can be examined and moved through with productions. This method also has the advantage of allowing for errors in memory of what was said-- ACT-R can retrieve the wrong word when trying to retrieve the correct next word, for example.
representation of desires in ACT-R: ACT-R is an architecture for modeling intelligence, and does not deal with general desires or emotions. I felt it necessary to include these omnipresent desires in a way the goal stack would not allow. Desires were represented like other chunks in memory, distinguished by the value of the ISA slot. Desires filled the ISA slot with "desire," and normal chunks filled the ISA with "concept." The normal use of the ISA slot was picked up with the new relation representation.
new relation representation: Since the ISA slot was being used in a different way, and to allow for multiple class-inclusion, a new "relation" chunk was created. Relationships connected chunks with "relations." The relationships are therefore subject to spreading activation like other chunks. Note that there is a difference between the relation and a relationship. "Meaning-relation" is an example of a relation, and "banana-sign means banana-concept" is a relationship. Both are subject to spreading activation.
relations are chunks in themselves: Relations are chunks in themselves (e.g. superclass-relation, meaning-relation). This way spreading activation works for relations as well as for chunks. This is an interesting cognitive claim that could be tested experimentally. The prediction is that presenting a fact activates the appropriate relations which in turn make other facts that use the same relations easier to retrieve.
The Primatech project was the first attempt to model ape language ability computationally. What was found was that the published data, on Chantek anyway, was not sufficiently constraining to get a testable model. Transcript data of actual conversations with Chantek would be most useful for modeling purposes, and are necessary for further progress on the cognitive model.