Most of the peer-to-peer applications build today
deal with storage sharing to exchange data or distributed computing to solve large problems.
An interesting application we are building is PeerCQ which is a peer-to-peer system based on
Continual Queries (CQs).
CQs are queries used for update monitoring in large-scale distributed
information systems. PeerCQ is the peer-to-peer way of building an Internet
scale event-driven update monitoring and information delivery system.
PeerCQ is a peer-to-peer system for
information monitoring on the web that uses CQs as its primitives to express
information monitoring requests. The primary objective of the PeerCQ system
is to build a decentralized Internet scale distributed system for monitoring
information change on the web. The system is aimed to be highly scalable,
self-organizing and support efficient and robust way of processing CQs.
This work is partially supported by the National Science Foundation under a CNS Grant, an ITR grant, a Research Infrastructure grant, and a DoE SciDAC grant, an IBM SUR grant, an IBM faculty award, and an HP equipment grant. Any opinions, findings, and conclusions or recommend ations expressed in this web site are those of the author(s) and do not necessarily reflect the views of the National Science Foundation or DoE.
/\top
PeerCQ system is an interesting application for two reasons. First it has an alternative and distinct approach to client/server based CQ systems. It has a peer-to-peer architecture and is totally decentralized. It distributes CQs that are long running entities, to the nodes of the system in order to optimize the execution efficiency. So it is more complex then basic peer-to-peer file sharing applications. It is more on the side of peer-to-peer distributed computing applications. But it is different than the conventional peer-to-peer distributed computing applications in the sense that it does not try to solve one large problem by partitioning it into parts and assigning each part to a node. In contrast PeerCQ system tries to execute lots of long running jobs by ensuring each job is assigned to a node at any time. The term long running is crucial here. It is not acceptable to break a CQ execution and resume it at some arbitrary time or take it over from the beginning. Once started a CQ has to run until its stop condition is reached. The second interesting property of PeerCQ system is its ability to integrate both node/peer information and user/CQ information into the load balancing scheme, which is a challenge in totally decentralized systems. By this way PeerCQ captures the existing heterogeneity among the users and peers of the system. However, most of the peer-to-peer protocols make the assumption that all nodes tend to participate and contribute equally to the system and assign responsibilities to peers with this assumption, which makes applications build on these protocols unable to capture the heterogeneity inside the system. /\top
The peers of the PeerCQ
system are users on the Internet that execute the PeerCQ servant application on
their machines. The term servant expresses that the peers are acting both as
clients and servers. The general scenario from the users point of view in PeerCQ
system is as follows:
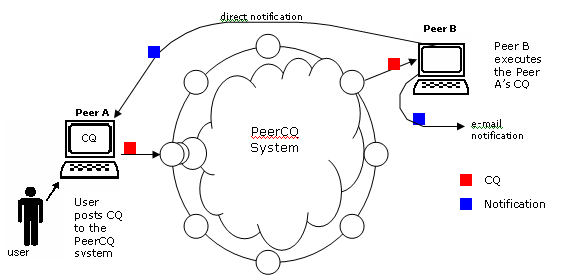
A user composes a CQ and posts it to
the system using its peer. The user’s peer sends this request to the PeerCQ
system. After that, the peer where this CQ will be executed is determined and
the CQ is assigned to that peer. Then the CQ starts execution. When the peer
responsible for executing the CQ detects an interested information update and
runs the query, it notifies the owner of this CQ, supplying it with the
resulting new information. This notification could be realized by mailing the
result to the owner's e-mail address or by directly sending it to the owners
peer if it is online at the time of notification. Note that, even if a peer is
not participating in the system at a given time, its previously posted CQs are
in execution at other places.
In the described scenario the user’s peer is located on the user side and
becomes a part of the system at initialization time of the servant application.
However, the user might be using a hand device or some device that is not
powerful enough in terms of resources to participate in the PeerCQ system as a
servant. In these cases the user can only be a client and forward its CQ’s to a
service provider that participates in the PeerCQ system in the regular way.
In PeerCQ system every peer
participates in the process of evaluating CQs. A peer joining the PeerCQ network
is assigned some CQs to process, and it can post a new CQ of its own interest.
This newly entered CQ is usually assigned to a different peer in the system for
processing. PeerCQ system combines three functionalities: data storage (storage
of CQs), processing (execution of CQs; i.e. update monitoring, trigger condition
evaluation and query execution) and delivery (notification service). CQs posted
to the system must be safely stored all the time and for each CQ there must
exist a peer executing it at any time.
/\top
Challenges
There are several challenges in
developing a peer-to-peer solution in CQ domain. First of all, the CQ domain is
complex. A CQ is a long running entity, which requires processing and has a
large state. At this point, balancing the workload equally over peers, safely
storing and smoothly executing CQs become important issues to focus.
Some problems that need attention in this peer-to-peer approach to CQ system are:
Smart service partitioning
How the load is balanced among the peers?
Is a peer’s contribution to the system configurable by the administrator of that peer?
Is the load balancing sensitive to the resource power and the desired contribution of the peer? In other words is it peer-aware?
What is the role of CQ subscriptions in peer load balancing?
Is the load balancing sensitive to the information coming from CQs? More concretely, does the assignment decision consider the specifics of the CQ at hand while determining the peer that will execute it? In other words is it CQ-aware?
When a peer enters the network, does it get some already active CQs to execute from other peers in order to balance the load? If so, how does this migration work?
When a peer leaves the network, which peers get the CQs that it was executing?
Failure
What will happen if the peer executing a CQ fails and how is this detected in the system?
Do failures have an affect on the correct execution of the CQs, since the CQs have a state while running and a simple start over method will not work all the time?
Trust
How trust-worthy are the peers?
How stable are the peers, are they entering and exiting the system so frequently that they are not helpful enough to execute CQs, since CQs are long running entities.
Is there a reason for users to stay connected to the PeerCQ system, in other words does the system favors the peers participating better?
Is there a protection mechanism against malicious peers that continuously post useless but resource consuming CQs.
Restricted users
Users behind firewalls might be restricted to access some information on the web. The target sources, that has to be monitored in order to execute a CQ might not be reachable to a peer assigned to that CQ. How PeerCQ system deals with those cases?