Sliding Window Joins over Data Streams
|
Sponsor
|
Dr. Ling Liu / Bugra Gedik
{lingliu, bgedik}@cc.gatech.edu
CCB 216 / CCB 263
|
|
Area
|
Databases
|
Problem
Boosted by the proliferation of Internet connections and availability of network connected sensing devices, we are experiencing an ever increasing rate of digital information available from on-line sources. As a result of this, management of fast data
streams has become a challenging problem, which requires solutions that will enable applications to effectively access and extract information from such data streams. Recently, database researchers have come up with the idea of Data Stream Management Syst
ems (DSMS), which try to solve this problem in a very similar way the DBMSs have solved the data management problem for traditional data bases. Some examples of prototype DSMSs are Aurora (Brown, Brandeis, MIT), STREAM (Stanford) and Telegraph (Berkeley).
Joins are key operations in any query processing engine. However, it is not possible to apply well-known join algorithms designed for traditional database relations, without any changes, to data streams. Traditional joins are blocking operations. The
y need to perform a scan on one of the inputs to produce all result tuples that match with a given tuple from the other input. However, data streams are unbounded, thus blocking is not an option. One natural way of handling joins on infinite streams is to
use sliding windows. In a windowed stream join, a tuple from one stream is joined with only the tuples currently available in the window of another stream. The windows defined over the streams are bounded, as new tuples get inserted into the windows, old
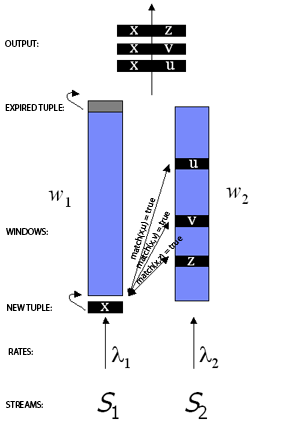
ones are removed. Some examples of such windows are "Last 100 tuples" or "Last 10seconds' tuples". The figure on the right illustrates a two-way windowed stream join.
Some application examples, that can make use of sliding window joins are:
- Finding similar news items from different sources (ex: CNN, Reuters, BBC)
- News items are represented by weighted keywords
- Perform windowed inner product join on weighted keywords
- Finding correlation between phone calls and stock trading
- Phone call streams {… (Pa,Pb)…} -> Pa calls Pb
- Stock trading streams {…, (Pb, Sx) , …} -> Pb trades Sx
- Perform windowed equi-join on person
- Pa hints Sx to Pb in the phone call
Students are expected to get familiar with the topic through reading the references [1,2,3,4]. The aim of this project is to study research issues, in particular, following issues related with sliding window joins over data
streams are of interest:
- Data Model: The commonly used model for data streams is that, each stream is a time ordered set of tuples. Each tuple is composed of possibly more than one attribute as defined by a schema. For instance, in the example 2 above, the phone ca
ll stream has the schema (Caller: String, Callee: String) . Most of the work on data streams has so far considered simple types for the attributes in a tuple. However, the example in 1 requires representing a news item as a tuple. This can be achieved by
defining a complex attribute, such as a weighted set valued attribute. In this case the join condition can be a threshold function defined over the similarity between the tuples based on a similarity metric.
- Workload Properties: Different assump
tions about the properties of the streams can be made, depending on the application at hand. For instance, some tuples may be more important than others; as a result, their inclusion in the output of the join may be more preferable. This information can b
ecome handy if it is not possible to compute the join exactly (possibly due to insufficient system resources) . In the example 1 above, news concerning national security may be of higher importance. In example 2, calls from insiders may be of higher inter
est. Another assumption can be that, there is a non-flat match probability distribution function for a newly received tuple that is compared to a tuple in a window defined over another stream, based on the difference between the timestamps of the tuples.
In example 2, there will be a time delay between a hint call and the action of trading a stock based on the hint. As a result, it is more profitable to compare a tuple received from the stock stream with tuples that are further inside the window defined o
ver the call stream. Another application which better illustrates the usefulness of this assumption is traffic monitoring. Assume there are three streams corresponding to three different locations on the traffic network. Each stream consists of object ide
ntifiers that indicate presence of the objects at the location represented by the stream. If we want to perform an equi-join on these streams to find the objects that has passed through all three points, we'll observe a difference between the timestamps
of the matching tuples from different streams. You can refer to [6] for more details about the latter assumption.
- Join Semantics: Windows can be user defined (time-based or count-based), in which case we have fixed windows and there is a
well defined output of the join. Or they can be flexible, in which case the system uses the available memory or CPU resources to maximize the output size (or the utility) of the join.
- Join Processing: Different types of processing can be used to perform the join operation. For instance, in example 1, an inverted index can be built over window contents, while in example 2 a hash-based index can be more suitable. It is imp
ortant to note that, as opposed to traditional joins, in stream joins we have to deal with the issue of dynamically maintaining the indexes built over the sliding windows as tuples enter and exit the window. This brings additional costs to indexing. Using
basic windows is an effective technique for dealing with such costs. See [5] for a detailed discussion of indexing sliding windows defined over data streams.
- Load Shedding Techniques: Data sources are push based in DSMSs. Which means that we do not have control over input data rates. They can be high and bursty. As a result, load on the system can exceed the capacity of the system, especially du
ring spikes in data rates. This results in increased output latency and also tuple dropping as a result of overflowing buffers. In order to keep up with the incoming rates of the streams, load shedding is usually needed in data stream processing systems.
Load shedding means doing less work, thus producing fewer (or in other words approximate) results. Load shedding is required for stream joins, when (i) stream rates are high, (ii) windows are large, (iii) join conditions are costly to evaluate. Different
techniques can be applied to shed load in stream joins, such as Tuple Dropping (random, low selectivity first, low valued first), Window Reduction [6], or Selective Processing (processing only certain portions of the windows). It is important to make use
of the assumptions described in Workload Parameters bullet when thinking about load shedding. Also, it is crucial that such load shedding techniques be adaptive to stream properties as these properties may change dynamically.
Deliverables
A report describing your approach to performing sliding window joins over data streams. Make sure you describe your data model, assumptions about workload properties, semantics of your join operation, type of processing you perform for evaluating the j
oin and how you handle load shedding. The report should describe why your approach is better than the others, ex. more generic, more efficient, more adaptive.
Evaluation
You will be graded on the quality of your report.
References
[1] B. Babcock, S. Babu, M. Datar, R. Motwani, and J. Widom. Models and Issues in Data Stream Systems. Proceedings of the ACM Symposium on Principles of Database Systems (PODS), 2002.
[2] J. Kang, J.F. Naughton and S.D. Viglas. Evaluating Window Joins over Unbounded Streams. Proceedings of the IEEE International Conference on Data Engineering (ICDE), 2003.
[3] L. Golab and M.T. Ozsu. Processing Sliding Window Multi-Joins in Continuous Queries over Data Streams. Proceedings of the International Conference on Very Large Data Bases (VLDB), 2003.
[4] A. Das, J. Gehrke and M. Riedewald. Approximate Join Processing over Data Streams. Proceedings of the ACM International Conference on Management of Data (SIGMOD), 2003.
[5] L. Golab, S. Garg, and M.T. Ozsu. On Indexing Sliding Windows over Online Data Streams. Proceedings of the International Conference on Extending Database Technology (EDBT), 2004.
[6] U. Srivastava and J. Widom. Memory-Limited Execution of Windowed Stream Joins. Proceedings of the International Conference on Very Large Databases (VLDB), 2004.
more available on request