
![]()
1994 AISRP Workshop
July 12-15, 1994 Karsten Schwan, College of
Computing
Fred Alyea, Earth and Atmospheric Sciences
M. William Ribarsky, Information Technology
Mary Trauner, Information Technology
Thomas Kindler, Earth and Atmospheric Sciences
Dilma Silva, College of Computing
Greg Eisenhauer, College of Computing
Yves Jean, College of Computing
Jeffrey Vetter, College of Computing Georgia
Institute of Technology
Atlanta, Georgia
In addition to its contribution toward understanding the complex
physical and chemical phenomena occurring in the earth's
atmosphere, atmospheric modeling is a grand challenge problem for
a number of reasons including the inordinate computational
requirements, the generation of large amounts of data in
conjunction with the use of extremely large data sets derived
from measurement instruments like those on satellites, and the
repeated processing and re-processing of data. Our group's
contributions to the areas of atmospheric modeling and high
performance computing are:
Global transport models are important tools for understanding the distribution of relevant atmospheric parameters like the mixing ratios of chemical species and aerosol particles [1]. Transport models are often coupled with a variety of chemical reaction mechanisms to describe selected chemical changes of the simulated species during transport. In addition, global transport models can be coupled with more local models, providing input data for air pollution models for example. The purpose of utilizing the transport model in this research is for the investigation of parallelism in transport model execution and for its use in answering scientific questions such as stratospheric-tropospheric exchange mechanisms or the distribution of species like the Chlorofluorocarbons (CFC's), Fluorohydrocarbons (CFHC's) or Ozone. The model's functionality focuses on transport processes.
The governing equation for the global transport of any atmospheric constituent is most easily described as in these equations.
The specific global atmospheric model implemented as part of this research represents atmospheric fields with spherical basis functions. Spectral models have some advantages over the grid-based models. For example, spectral models naturally conserve the area averaged mean square kinetic energy and the mean square vorticity of wind fields (that is, they scale properly), whereas in grid based models these quantities are either not conserved or require additional computation when such conservation is important [2]. Despite such advantages, grid based models have found wider acceptance in recent research in part because (1) they are believed to be easier to parallelize and to give rise to larger amounts of parallelism compared to spectral models, and (2) they are believed more easily coupled with grid based models simulating local phenomena (e.g., pollution modeling).
This work demonstrates that the parallelization of a spectral global transport model is quite efficient, and that this parallelization can be performed such that it scales to massively parallel machines (i.e., machines with thousands of processors). The specific parallelized model simulates the transport of atmospheric constituents by expanding the fields of interest into spherical basis functions and solving the governing differential equation with a spectral approach. As a result, one specific issue addressed by our work is the efficient implementation, representation, and sharing of the global spectral information shared by all of the spectral model's computations, while the model's grid-based data is decomposed across different processors' memory units. This is a scalable model. Currently we are using spectral data consisting of up to 253 complex spectral coordinates (for 22 waves) or 9xx complex spectral coordinates (for 42 waves) per level of the stratosphere (up to 63 levels, covering from 0 to 50 km above the surface) which must be shared across all processors of the machine. At the same time, the grid data consists of up to 2048 complex numbers (64 longitudes by 32 latitudes) per level and must be shared only by neighboring gridpoints. Extensions of this model which also address chemical phenomena such as production and destruction are shown to further improve parallel program performance. This prompts us to expect equally good or even improved performance for more complex atmospheric models based on spectral methods, including the most powerful existing general circulation models (GCM).
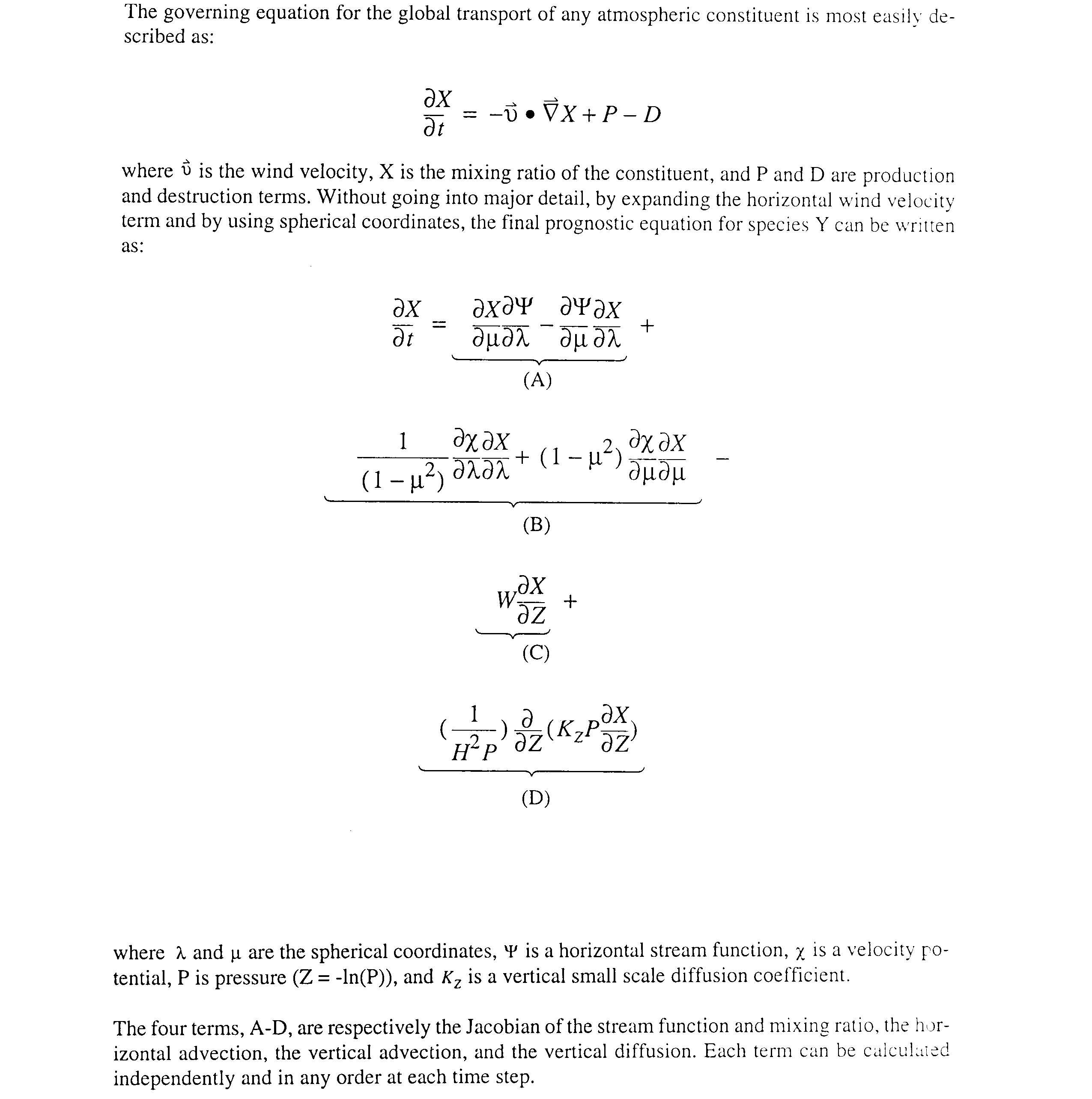
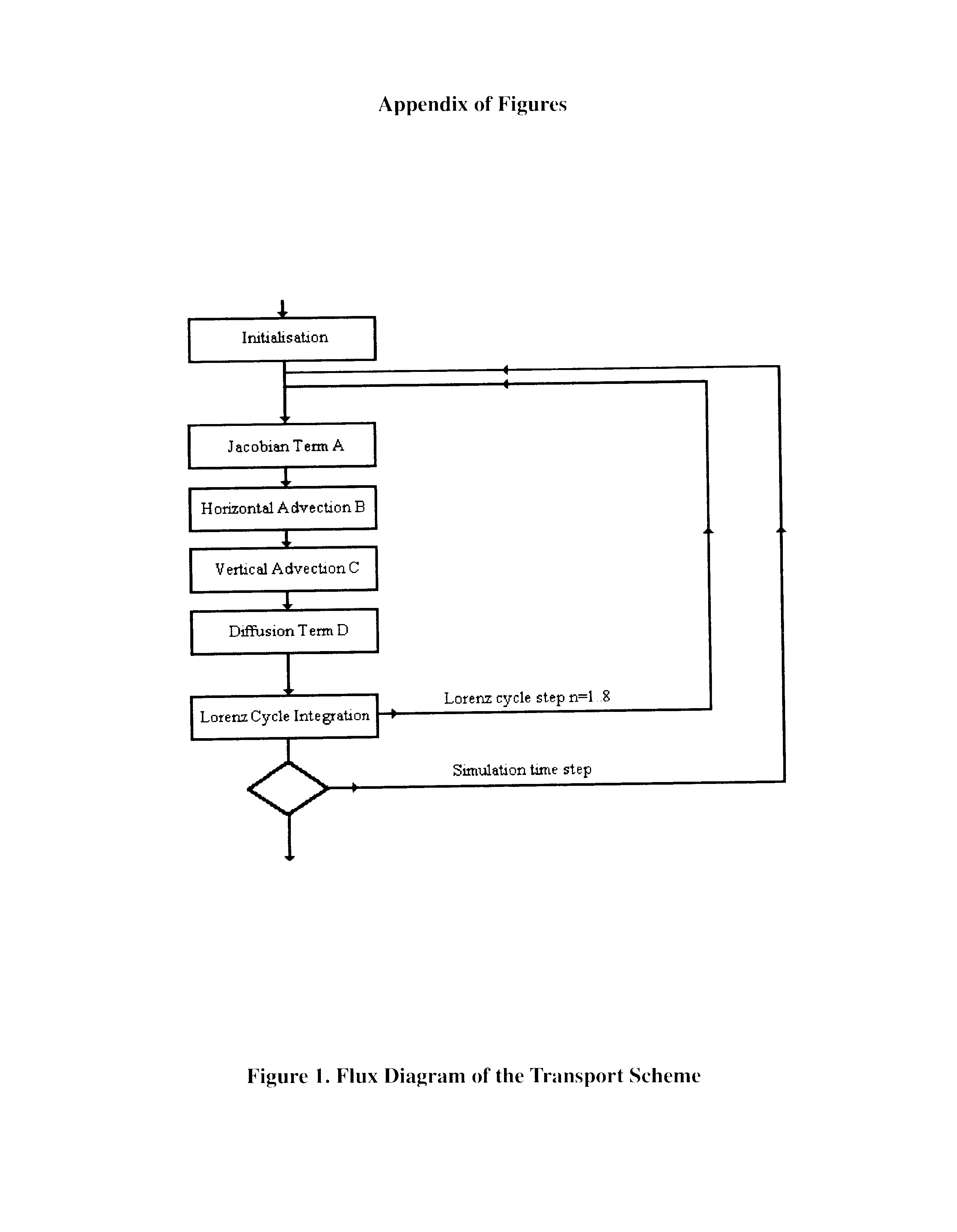
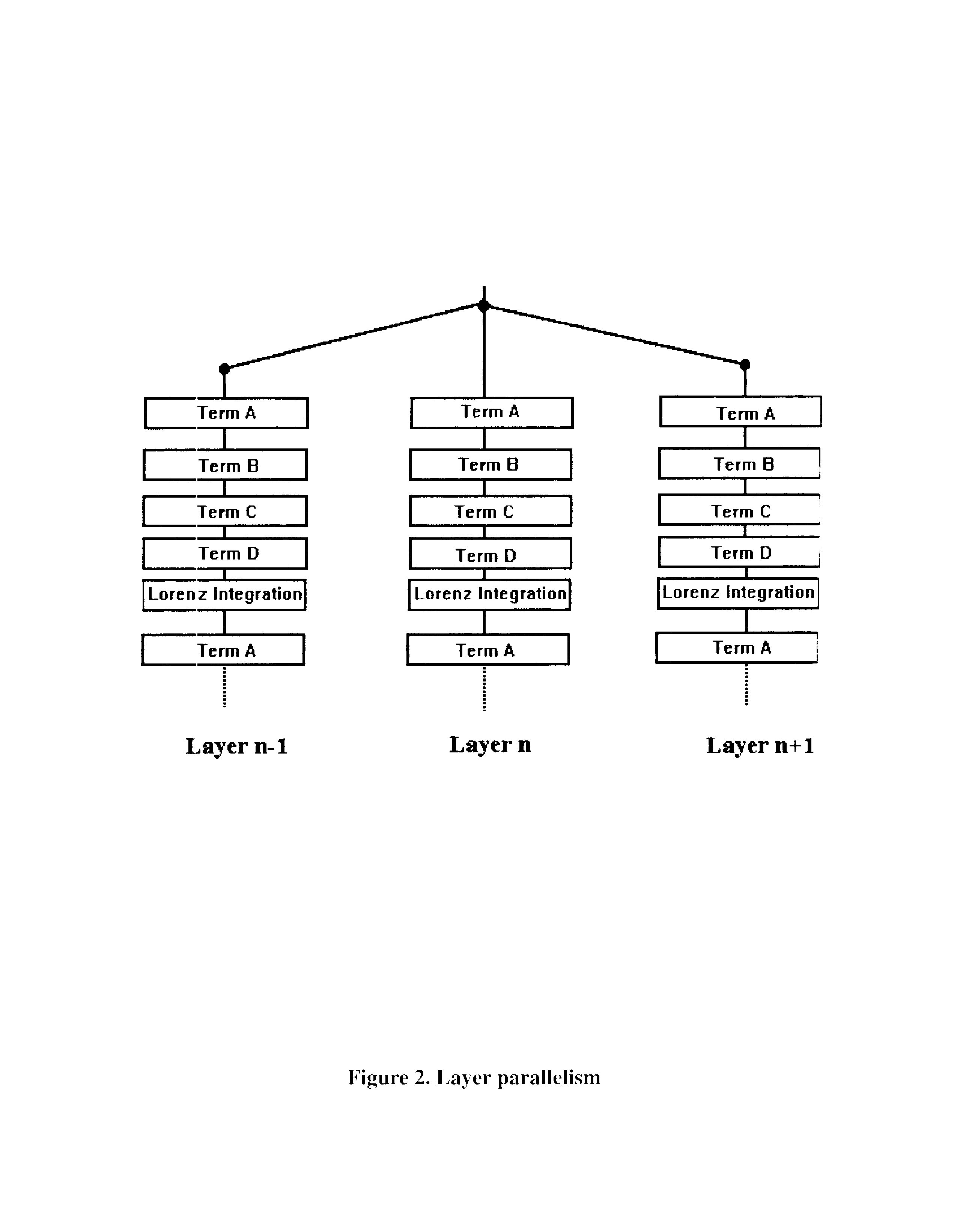
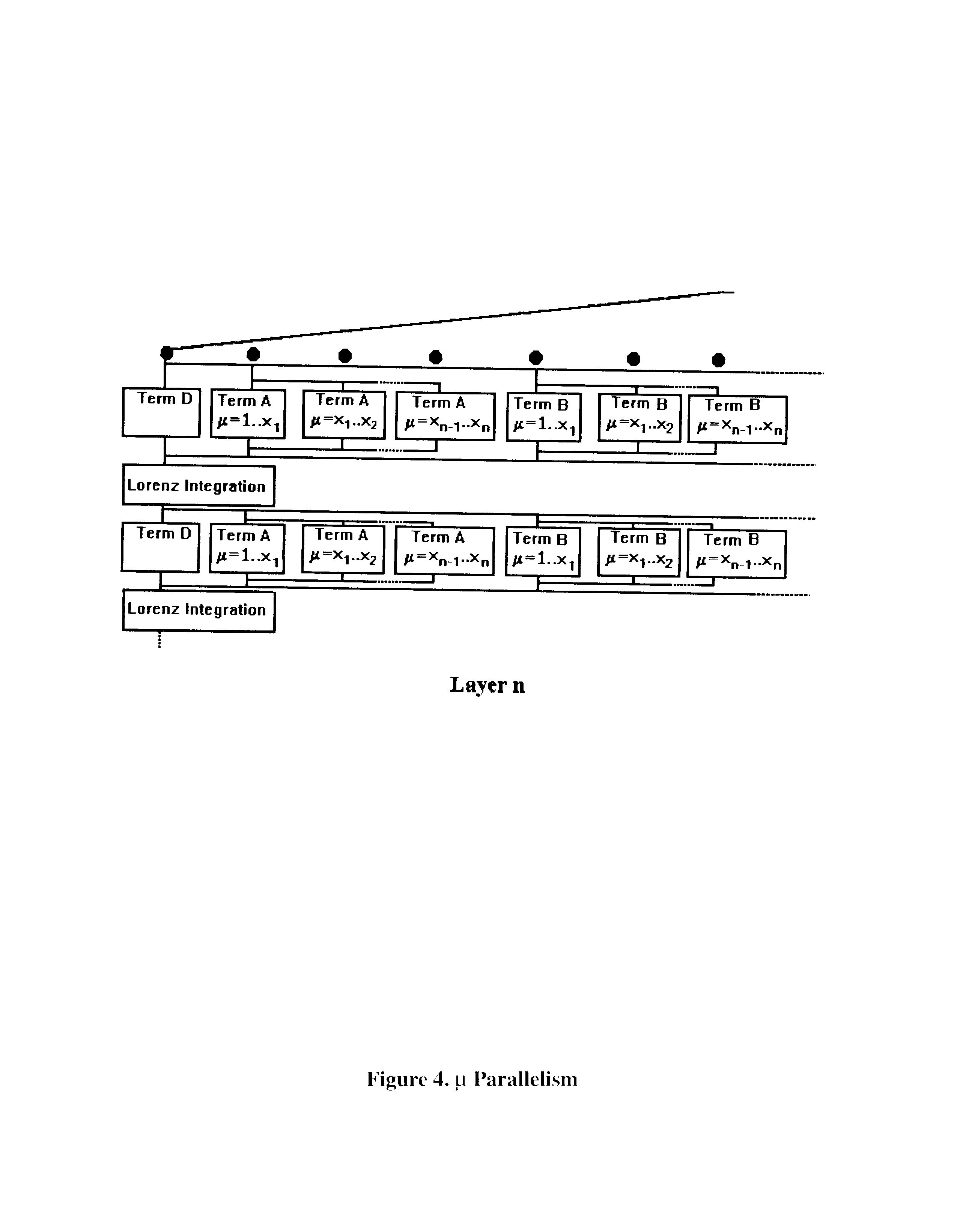
Figure 1 shows the basic, sequential implementation of our model. Here, while the terms can be calculated in any order, we show terms A-D being calculated one after the other. Figure 2 shows the first, simple methodology for parallelization, where each layer is calculated independently on a different processor. Figure 3 goes one step further to show the Parallelization of the A-D calculations within each layer. And Figure 4 goes on to show the Parallelization of the calculation of each term by latitude.
The application is written using Cthreads, a user-level threads package that allows easy control of thread-based parallelism and provides portability between a variety of shared-memory multiprocessor and uniprocessor platforms. On the KSR, Cthreads is implemented on top of Pthreads, a native kernel-level threads package. The advantages of Cthreads include increased performance compared to Pthreads for thread creation, context switches, and synchronization. Cthreads also gives users the flexibility to design and use threads primitives customized to their applications.
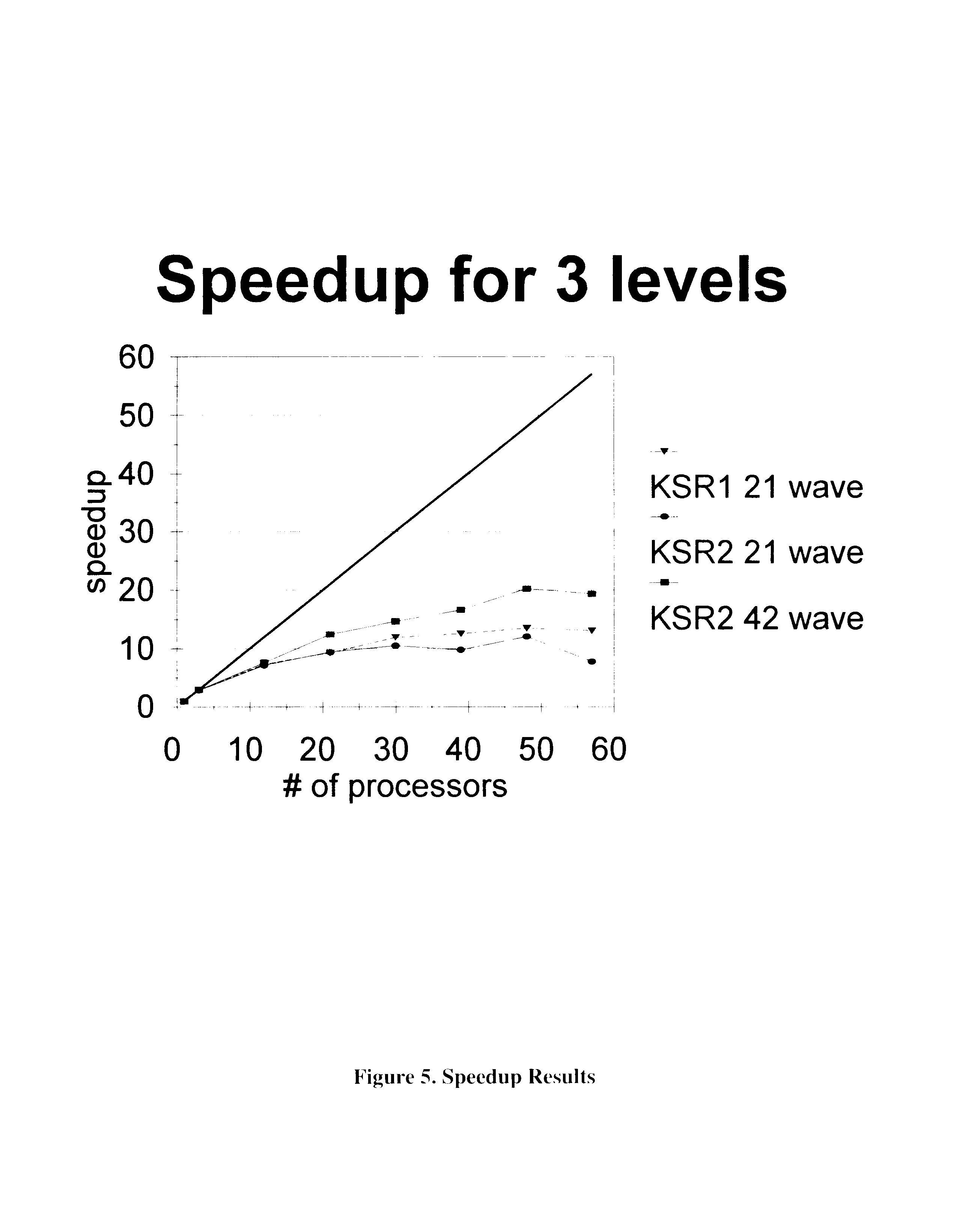
Figure 5 shows the speedup of the model thus far. The solid line designates the ideal speedup. Several things can be seen in this figure. First, due to the ring architecture of the KSR series systems, a slight drop in performance can be seen at 32 processors. As the model begins to move on to the second ring, some additional latency become apparent. This latency seems to balance out by the time we reach 40 processors.
Georgia Tech has quite recently installed one of the first KSR2 systems in existence. A few days before the preparation of this paper, we were able to make several model runs on our KSR2-64. Preliminary results show very little difference between the KSR1 and KSR2 for the 21 wave version of the model. But as we increase resolution by going up to 42 waves, we see that performance has improved nicely.
These experimental runs were made on only 3 levels in the stratosphere. We see a reasonable performance increase up to 50 processors. Considering that the UKMO datasets are covering 37 levels, we would anticipate that our parallel model would scale nicely to a system with around 650 processors.
Finally, we see that our speedup is roughly half of the optimal speedup. We should point out that, in parallelizing the transport portion of the model, we are parallelizing the spectral component of the whole production, destruction, and transport calculations. As we add the gridpoint calculations for the production and destruction components, we should see a great deal of improvement in the parallelization and our curve should move up significantly toward the ideal curve.
Interactive steering is defined as `the on-line configuration of a program by algorithms or by human users, with the purpose of affecting the program's performance or execution behavior'. Steering can range from rapid changes made to the implementation of single program abstractions like a mutex lock to the user-directed improvement of load balance in a large-scale scientific code. In either case, program steering is based on the on-line capture of information about current program and configuration state, and it assumes that human users and/or algorithms inspect, analyze, and manipulate such information when making and enacting steering decisions. For example, work load distribution information of an application can be captured by a monitor running along with the application, and be used by a steering mechanism to direct dynamic load redistribution to achieve load balance among participating processors.
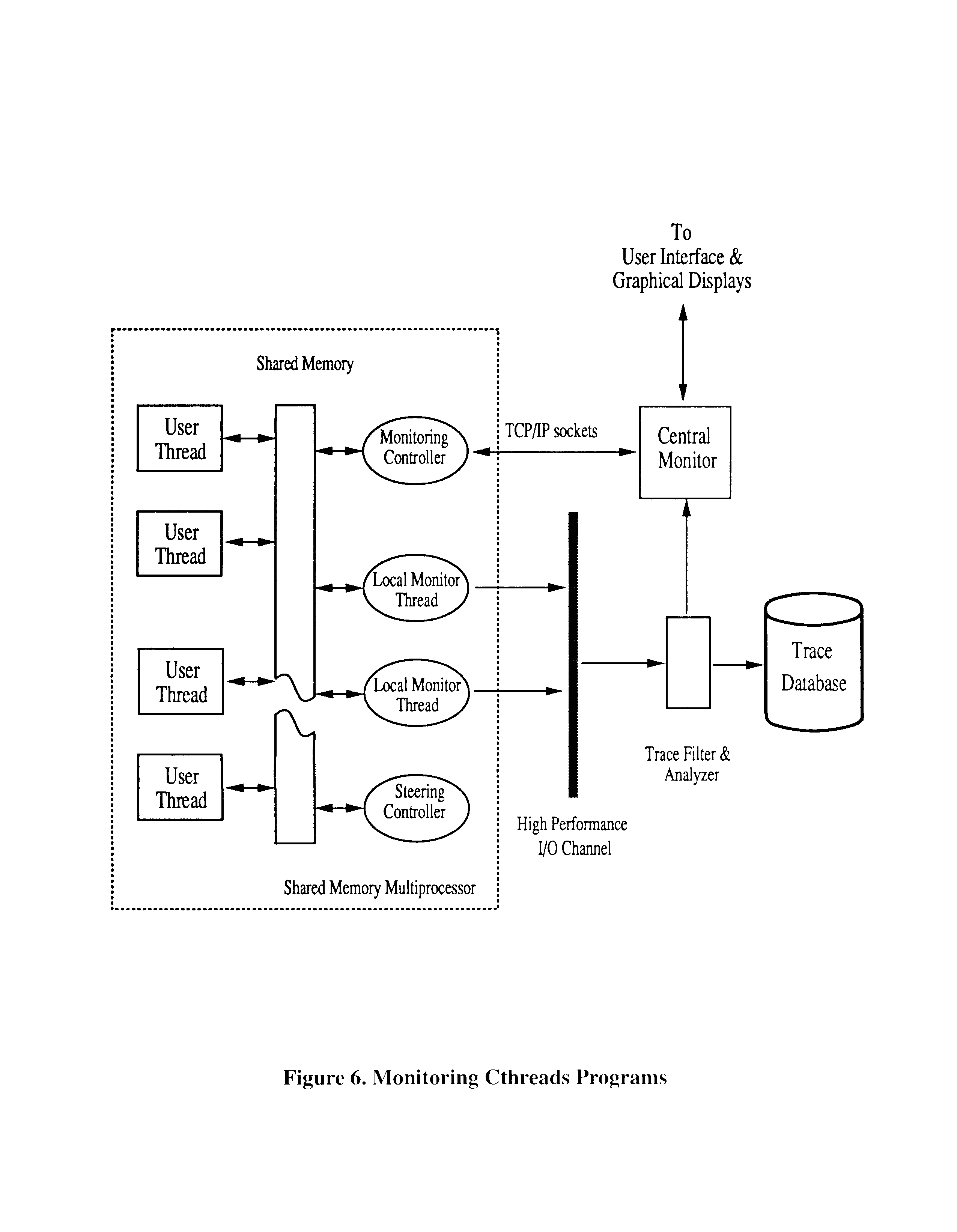
The monitoring and steering system we propose should consist of four conceptual components (Figure 6): (1) a monitoring specification and instrumentation mechanism, which consists of a low-level sensor specification language and a high level view specification language, and an interactive instrumentation tool, (2) mechanisms for on-line information capture, collection, filtering, and analysis, (3) mechanisms for program steering, and (4) an interface with both the end user and the visual data representation component.
The application code is first instrumented with the sensors and probes that implement the sensor and view specifications. Language-based monitoring specification allows users to define application-specific type information concerning both the program and performance behaviors to be monitored and the program attributes based on which steering may be performed. The actual instances of sensors and probes, that generate trace data which is collected and analyzed by the monitoring mechanisms and that may be used by the steering mechanisms to trigger steering actuators, are created at the program's run-time. Therefore new instances of sensors and steering actuators may be defined for newly created execution threads, and user programs and/or the user interface or analysis/steering algorithms can directly interact with the run-time system in order to control program monitoring and steering.
When the application is running, program and performance information of interest to the user and the steering algorithms is captured by the inserted sensors and probes, and is collected and partially analyzed by the run-time monitoring facility. The run-time monitoring mechanism essentially consists of monitoring data output queues attaching user threads being monitored to a variable number of threads performing steering and low-level processing of monitoring output. The partially processed trace data is fed to the steering mechanism to effect on-line changes to the program or the execution environment to improve the overall performance of the application, and to the graphical displays to show the application's program and performance behaviors to the user (Figure 7). The trace data can also be stored to a trace data database for future postmortem analyses. Further on-line filtering and analyses are performed before they can be consumed by the steering mechanism or the graphical displays. The monitoring, steering and user interaction controllers activate and deactivate sensors, execute probes or collect information generated by sampling sensors, maintain a directory of program steering attributes, and also react to commands received from the monitor's user interface. For performance, these controllers are physically divided into several local monitor controllers and a steering controller residing on the parallel program's machine and able to rapidly interact with the program, and a central monitor controller typically located on the front end workstation or the processor providing user interface functionality.
We are building the visualization/analysis system within the SGI Explorer dataflow environment. This environment gives us flexibility and extensibility and a rich set of visualization modules. It also allows a distributed approach for simulation, visualization, and analysis that fits our model. Although built within the SGI Explorer environment, the VA system will have new functionality by offering user-defined visual representations, new probes for focusing and conditional analysis of complex data, controllable animations, and mechanisms for steering simulations.
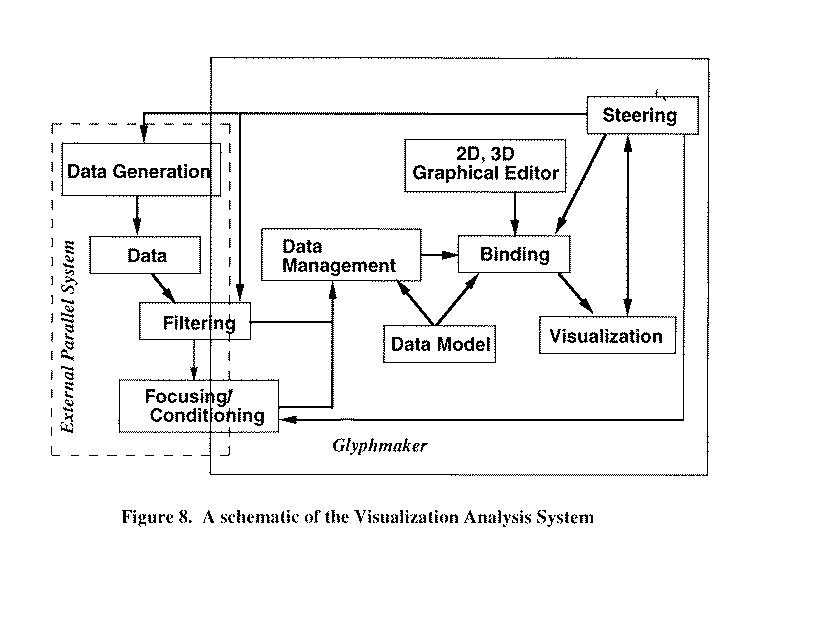
The schematic in Figure 8 shows our general VA system. Data generation, data filtering, and data focusing and conditioning will be performed on an external (i.e., parallel) set of processors in a distributed environment (denoted by the dotted outline). Some of these function could also be shared by the graphics workstation, depending on the complexity of the computation or size of the data, and thus straddle the dotted line. After the data is generated and filtered, it is sent to the Explorer environment (inside the solid outline) on the graphics workstation. The VA system is built on a set of tools we have developed called "Glyphmaker" [3,4], which we have extended for this application. Within the VA system (and Glyphmaker) is a data management scheme founded on a customized data model. The model provides great flexibility in access to the data because it builds up the data structure in layered parcels (called "baskets of eggs"), the lowest layer being the original data followed by filtered or conditioned versions and then by binding rules for the geometry to which the data is mapped. This structure allows a two-way path from original data to geometry and back. This is particularly powerful because one can select any set of geometrical objects and get back the detailed original data. Thus the user has a process for quantitative analysis of the data based upon a picture that she sees.
The data model and the module design we have implemented allow the sending and receiving of streams of baskets of eggs. Thus our structure supports time step animation, the breaking up or conditional isolation (based on spatial boundaries or limits on other variables) of data, and the reduction of very large datasets to manageable units for visualization/analysis. Each stream of baskets may be passed through the binder where the user may choose 3D visual objects (called glyphs) and mappings of the data onto their perceivable features (e.g., position, color, size, shape distortion, transparency, etc.). The user can either choose glyphs from a library or make her own using a simple 3D editor. In this way the user has great control over the visualization of her data and over what is visualized. She can choose visual representations that highlight features of interest and can follow complex time and space development of several variables at once and the correlations between them.
To show the VA system in action, we present in Figures 9-11 some preliminary visualizations of data from the parallel simulation. Here spectral data is taken from the simulation, transformed to gridded data on the fly in the VA system, and rendered. The 3D visualizations show how multiple layers at different altitudes (e.g., Figure 9) can be studied at once to correlate behavior between layers. These multiple layer views have been shown to be quite effective in revealing the structure and time dependence of complex atmospheric data [5]. Figures 9-11 all show the 3D structure of the carbon-14 mixing ratio from a transport simulation. Other correlated variables, such as wind speed and air pressure, could be depicted as well. The user also has the choice to interactively rotate and animate her selections from the simulation data. Figures 10 and 11 show the mixing ratio data in an alternative projection mapped onto the world sphere. Projections such as these provide an undistorted view of atmospheric data that can be quite useful in studying time dependence [5]. Thus in Figure 10 we show the time-dependence over 20 days of an isosurface in the middle of the range of mixing ratio values (earliest time at upper left and later times in a clockwise sequence). In the VA system, we are building efficient ways to depict time-sequenced data, by either rendering on the fly (forward or reverse) using memory caching mechanisms or by collecting images for playback. Figure 11 shows a range of mixing ratio values with color indicating the value of the contour. (The lowest value is mapped to red and the highest to blue.)
In our VA system we will go well beyond these visual representations by providing mixed representations involving combinations of glyphs and surface or layer visualizations (as presented here). We will also develop advanced glyphs such as fast volume-rendered representations or interactively-placed probe glyphs that sample surrounding data variables.
We will use a number of methods to make our research available to the NASA community and to the scientific community. Each year of the project, we will develop reports which will be distributed through NASA and the Georgia Tech CoC/GVU technical report series and we will prepare scientific papers for publication in journals or conference proceedings.
We will develop Mosaic-based descriptions of the project for placement on the Georgia Tech (CoC/GVU) and NASA WWW servers. The Mosaic descriptions will be augmented by graphics, animations, and eventually copies of the steering, visualization, and analysis codes with documentation.
A version of the code with documentation will be kept in an anonymous ftp directory at the HPC and GVU centers, accessible by Gopher and other information discovery facilities.
As our steering, visualization, and analysis tools mature, we will seek data (both simulational and observational) from other NASA researchers. This will provide a set of steering and visualization examples and will also provide feedback for improving the tools.
The next steps in this research will address model parallelization, monitoring and steering tools, and data visualization. Concerning model parallelization, we will (1) experiment with an advance parallelized version of the atmospheric model in order to understand the parallel program performance parameters and visualization and steering attributes of such models, coupled with (2) the development of a production version of the model able to be used for research in the atmospheric sciences. Part of (2) is the development of uniform binary file input and output formats across the C and Fortran languages used by our researchers. Both the file formats and the production model version will be made available to the research community via remote ftp and offer sample atmospheric and model data.
Concerning program monitoring and steering, programming libraries both for C and to a limited extent, for Fortran programs will be developed and made available for several uniprocessor and multiprocessor platforms, including SGI workstations, SUN Sparcstations, and the Kendall Square KSR1 and KSR2 multiprocessors. An instrumented CThreads library offering on-line program monitoring support is already available from Georgia Tech via remote ftp. Monitoring information output formats will be interoperable with the self-describing file formats developed for the Intel Paragon machine and will also use the self-describing binary file formats developed by our group for the manipulation of atmospheric data. Steering libraries will be developed using standard Motif-based user interfaces and will also use the self-describing binary file formats developed by our group for inter-machine interactions. Both direct socket connections among different machines and PVM-based communications will be employed.
Data visualization tools are based on the SGI Explorer environment. Our initial work has concerned the on-line input of model input and output (during model execution) data into the Explorer environment, followed by the on-line use of Explorer-based visualization tools. Both Tech-developed tools (the Glyphmaker) and externally developed visualization primitives addressing atmospheric data will be employed in this work. Extensions of the Glyphmaker tool will specifically address on-line visualizations of the complex and 3D data sets used by atmospheric scientists. In addition and in collaboration with atmospheric scientists, data visualizations will be coupled with program performance visualizations for interactive viewing and then steering of the model codes generating such data. The hope is to assist end users in the rapid experimentation with alternative model attributes and data inputs. The resulting complex, multi-machine and interactive programs will be the basis for our future research investigating the data sharing requirements of modern supercomputer applications across multiple parallel and sequential machines.
[1] P.J. Rasch and X. Tie and B.A. Boville and D.L. Williamson,
"A three-dimensional transport model for the middle
atmosphere", J. Geophys. Res., 1994, Vol. 99, pp 999-1017.
[2] W.M. Washington and C.L. Parkinson, An introduction to three-dimensional climate modeling, Oxford University Press, 1986.
[3] William Ribarsky, Eric Ayers, John Eble, and Sougata Mukherjea, IEEE Computer. "Using Glyphmaker to Create Customized Visualizations of Complex Data." (July, 1994).
[4] William Ribarsky, Jack Tumblin, Gregory Newton, Robert Nowicki, and Jeffrey Vetter. "Glyphmaker: An Interactive, Programmerless Approach for Customizing, Exploring, and Analyzing Visual Data Representations." Report GIT-GVU-93-26 (1993).
[5] Lloyd A. Treinish. "Visualization of Stratospheric Ozone Depletion and the Polar Vortex." IBM Research Report RC 18912 (82596) 5/21/93.
Figure 1. Flux Diagram of the Transport
Scheme
Figure 2. Layer parallelism
Figure 3. Term Parallelism
Figure 4. Micro Parallelism
Figure 5. Speedup Results
Figure 6. Monitoring Cthreads Programs
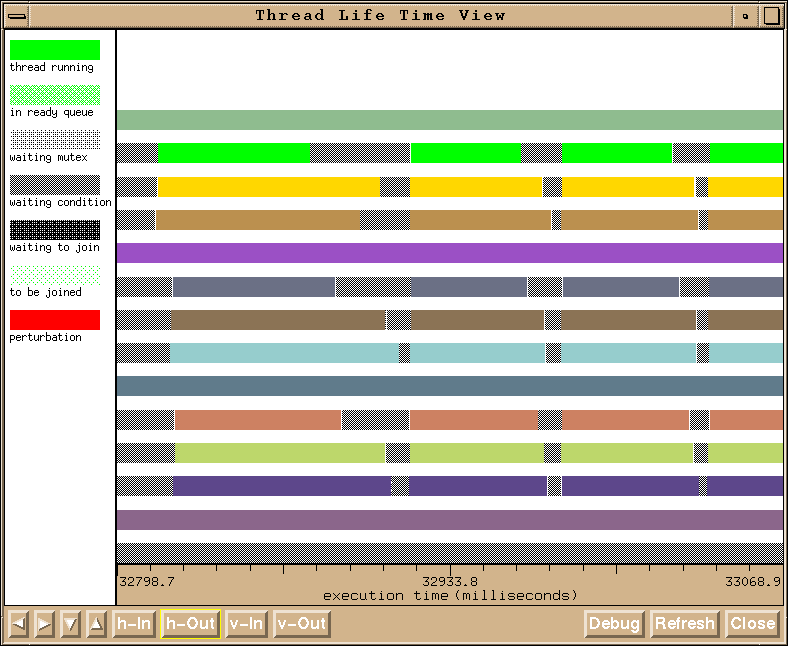
Figure 7. Thread Information View
Figure 8. Visualization/Analysis System
Figure 9. Multiple Layer Atmosphere Visualization
Figure 10. Time-dependent Isosurface Mixing Ratio Data Projected on the World Sphere
Figure 11. Contours of Mixing Ratio Data Projected on the World Sphere
Steering
of Parallel Simulations
![]()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}