Sketch-Based Image Synthesis
Cusuh Ham
cusuh@gatech.edu

Introduction
Recently, there has been an increase in popularity of artwork generated by computers. The goal of sketch-based image synthesis is to generate some image, photorealistic or non-photorealistic, given the constraint of a sketched object. This allows non-artist users to turn simple black and white drawings into more abstract, detailed art.
Understanding images is still a challenging problem in computer vision, nevertheless going in the opposite direction to generate a realistic image. Especially in this particular case in which we are working across two domains, sketch and image, it is difficult to completely rely on the computer for the entire image synthesis process. Previous approaches use texture synthesis techniques on a pair or set of images, but it is not as simple as just applying such methods to a very simple sketch which contains much less content than a typical image. In addition, evaluating the resulting generated images is difficult since humans are subjective in deciding what pieces of art look "good" or "bad."
We propose several different methods of sketch-based image synthesis. First, we explore the results of using style transfer algorithms on pure sketch-image pairs for generating both photorealistic and non-photorealistic images. Next, we use a different network architecture for getting the feature representations of the input pair. Finally, we combined the queried results of sketch-based image retrieval with the sketch itself as an intermediate step in the process of generating paintings from sketched objects.
Related Work
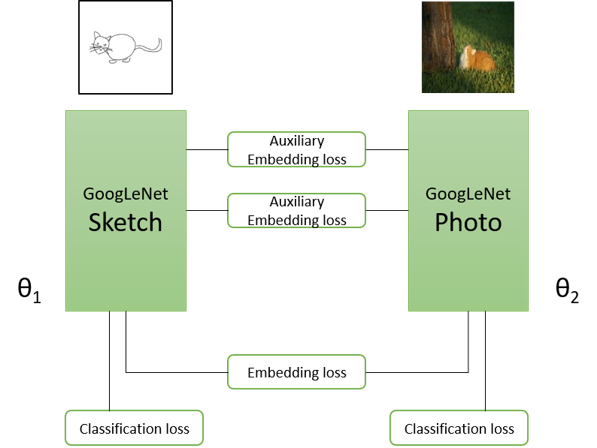
Sketch-based image retrieval: There are several approaches for retrieving images from a sketch query. Most recently, Sangkloy et al. [5] introduce a dataset of 75,471 sketches of 12,500 objects across 125 categories with which they train an adaptation of the GoogLeNet architecture into a triplet network. The adaptation allows the network to learn across both the sketch and image domain and learn a shared feature space between the two. Using this architecture, they achieve 37.1% accuracy for K=1 recall.
Image synthesis with neural networks: There has been raised interest in the use of deep convolutional neural networks (dCNN) for more generative tasks, such as texture synthesis. The works of Gatys et al. [2] utilize these dCNNs to transform the correlations of texture features of the "style" image within each layer of the network into a set of Gram matrices as well as to capture the high-level content of the "content" image. They use the VGG-19 network [6], which is trained only on images from ImageNet.
Another approach to image synthesis is using generative adversarial networks such as by Radford et al. [4]. In this approach, there are two networks, one playing the role of the discriminator and the other playing the role of the generator. Iteratively, the two play a minimax game against each other in attempt to optimize both the discriminative and generative sides. Ultimately, the generator should be able to produce more realistic images than such style transfer methods.
MRF-based image synthesis: As a follow-up to the style transfer method presented by Gatys et al., Li et al. [3] propose the use of generative Markov random field models with dCNNs to work for both photorealistic and non-photorealistic image synthesis. They replace the correlations captured by the Gram matrices with an MRF regularizer that maintains local patterns of the specified "style" and use the same VGG-19 network trained only on images.
Approaches and Results
StyleNet with VGG-19: In the original paper, input pairs/sets of a "content" image with a "style" painting are used. With this, the spatial layout of the content image is preserved as much as possible while it is being colorized and texturized to match the appearance of the style image. We choose to use an input pair of a sketch (content) and its directly corresponding image (style) to see if the network is able to understand the sketched object and transfer the characteristics of a realistic photo to the object. The results are shown in the table below:
 |
 |
 |
 |
 |
 |
 |
 |
 |
MRFs with VGG-19: Li et al. emphasize the major difference between their work and the work of Gatys et al. is the use of a local constraint instead of a global constraint, which results in the network's ability to work better for the photorealistic image synthesis task. Again, we choose to use an input pair of a sketch "content" and the directly corresponding "style" image, and the results are shown below:
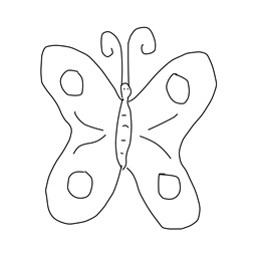 |
 |
 |
 |
 |
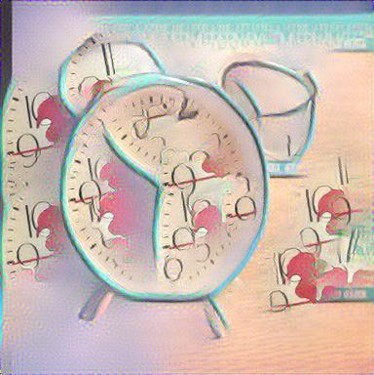 |
 |
 |
As seen above, StyleNet was not able to produce impressive results--the texture of the style image was not appropriately transferred to the sketch. However, the MRFs produced promising results in being able to better transfer the style image to the appropriate areas of the sketch, especially as seen in the butterfly and airplane examples. It was interesting to see some depth/dimension being added to the alarm clock sketch. With these results, we speculated the use of the GoogLeNet triplet network in place of the default VGG-19 network in order to get better features and correlations across the two domains.
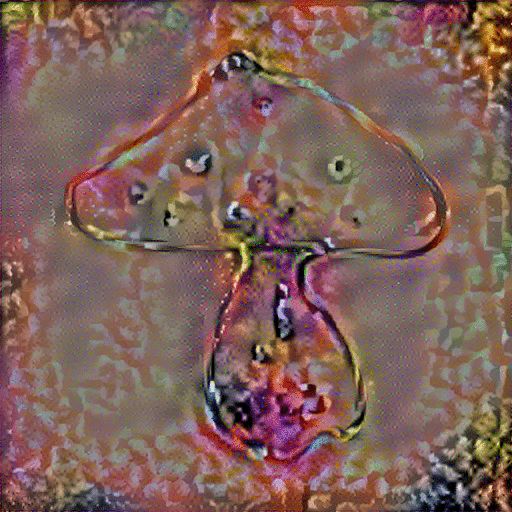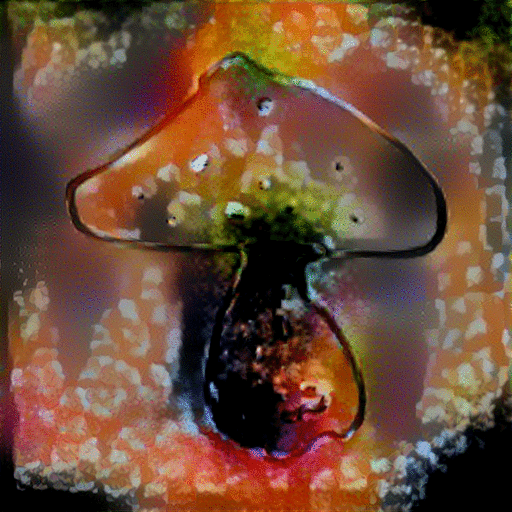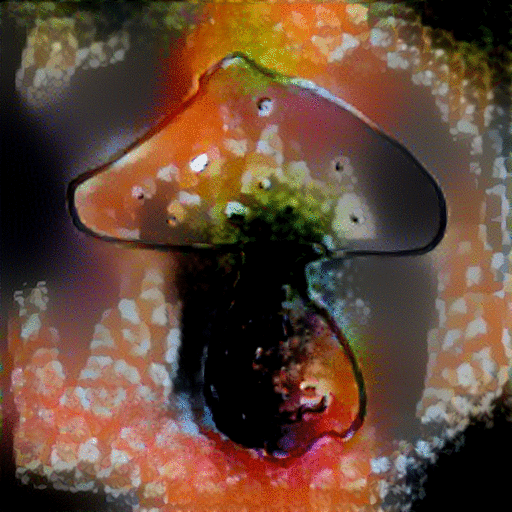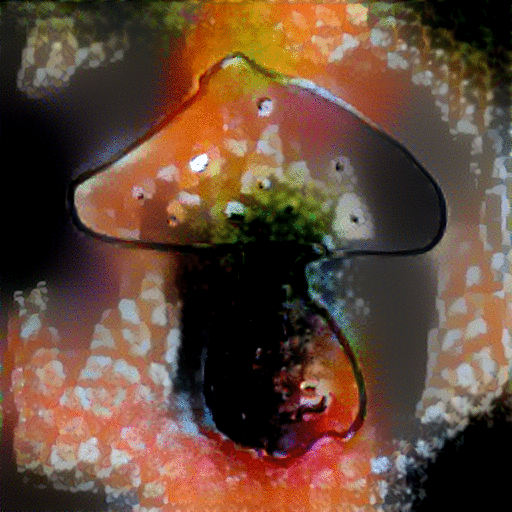
StyleNet with GoogLeNet Triplet: Because the original VGG-19 network was only trained on images, we did not expect it to be able to understand the sketch inputs. Thus, we proposed to replace the model with the GoogLeNet triplet network presented by Sangkloy et al. which was trained on both sketches and images. We needed to make modifications to the original implementation which was only compatible with single networks.
We experimented with inputting the sketch and image to their respective sides of the network and inputting both sketch and image to only the photo side of the network, as well as toggling the content-to-style ratio. When the sketch and image were inputted to their respective sides, the only direct correlations between the two come from the last layer, so we specified to only use that specific layer for the synthesis process. However, when the sketch and image were both inputted to the photo side of the network, we used the same approach as the original implementation to use multiple style layers and a single content layer for synthesis. The results are shown below:
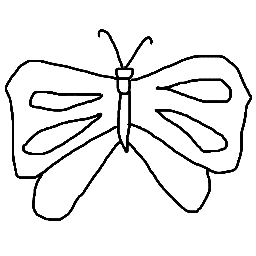 |
 |
 |
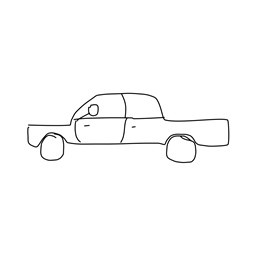 |
 |
 |
Across the various content-to-style ratios we experimented with, we saw that emphasizing more of the content image ultimately produced the sketched object with colorful noise added across the photo. Lowering the ratio to emphasize more of the style overall colorized the sketch more, but mostly only along the specific lines of the sketch. In comparison to using StyleNet with the default VGG-19 network, this approach performed a little better in focusing the style transfer to the boundaries of the sketch rather than across the entire sketched image space.
Average Images: We also wanted to explore the task of synthesizing non-photorealistic images, or in the case, paintings. We believed one of the major issues the networks in the techniques we were using was that because the sketches are very simple, especially in comparison to a typical image, they contain a lot less dimension and content. The sketches are made of solid black lines against a white canvas with no shading involved. Thus, we propose the use of average images.
In order to the provide the networks more information of the content image, we input an average image instead of a sketch as the content source. In order to generate the average images, we input a sketch into the same GoogLeNet architecture from Sangkloy et al. and retrieve the top k resulting images. We run a Canny edge detector [1] on the retrieval results to get the edge versions of the images. Then, we use FlowWeb [7] to find correspondences among the sketch and the edge versions of the retrieved images to better align the images. Finally, using the correspondences found, we transform the original version of the retrieved images and average the resulting warped images. The queried sketch is also overlayed on top of the average image.
The average image using the top k=1,2,5,10,20 retrieval results are shown below:
 |
 |
StyleNet with Average Image: With these aligned and averaged images, we hope to provide the network with more content and depth than the original sketch input. In addition to replacing the sketch content input with the average image of the top k=5 retrieved images, we also replace the style image with one of various famous paintings, including The Scream" and "The Woman With A Hat." The resulting generated paintings are shown below:
 |
 |
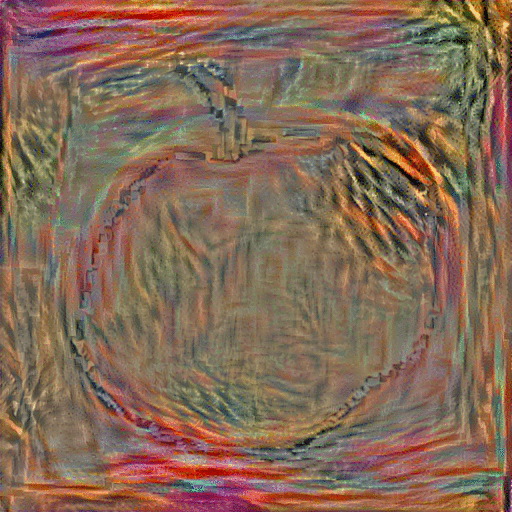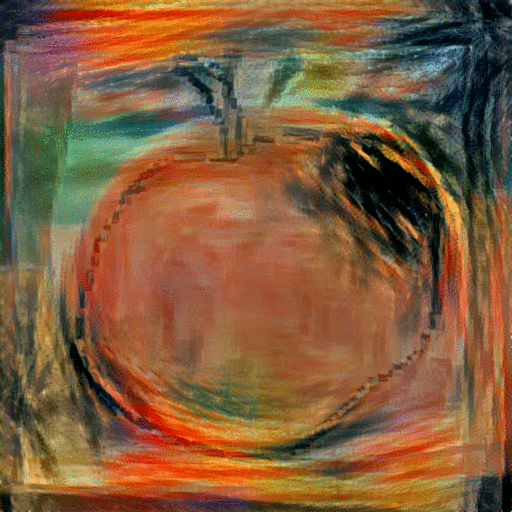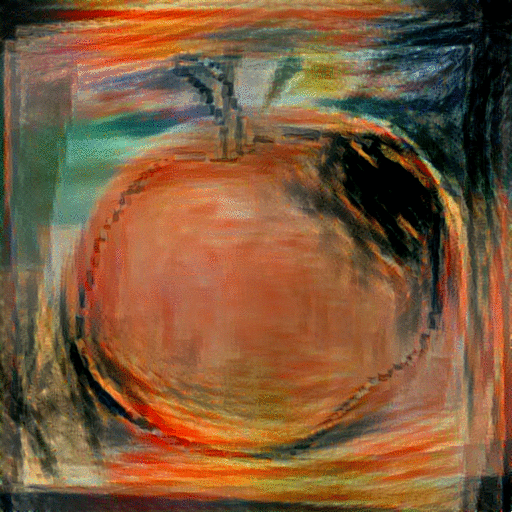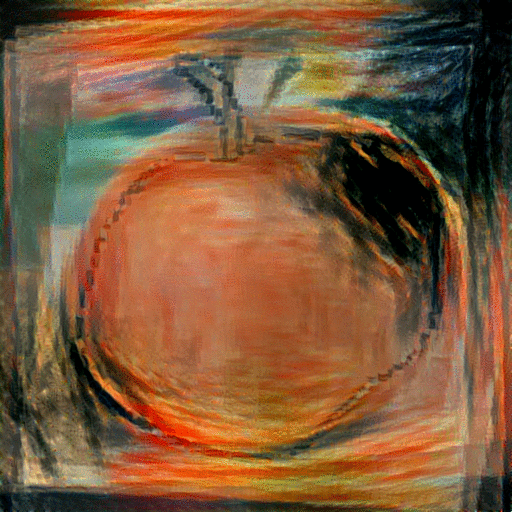 |
 |
 |
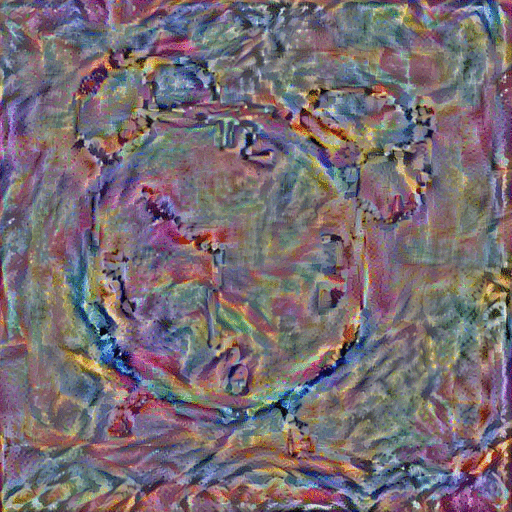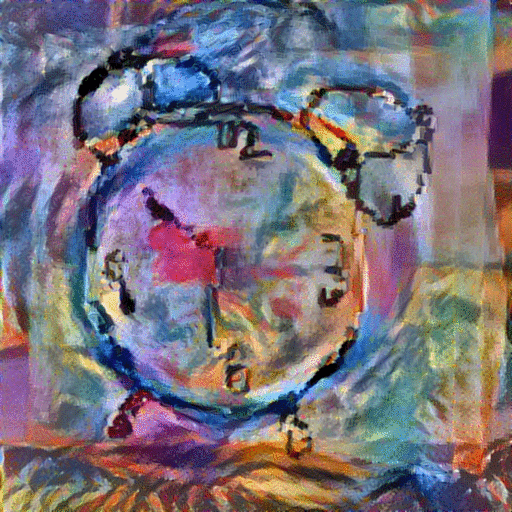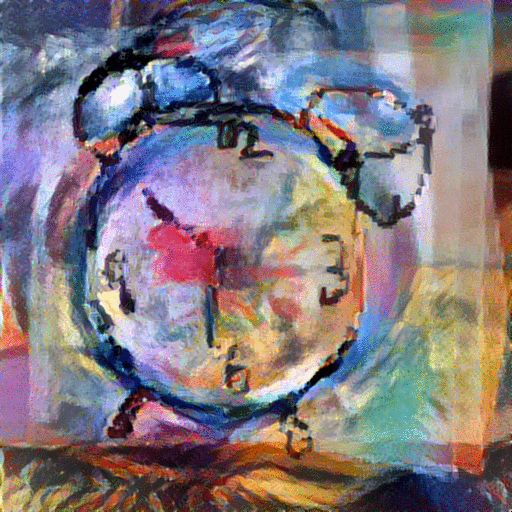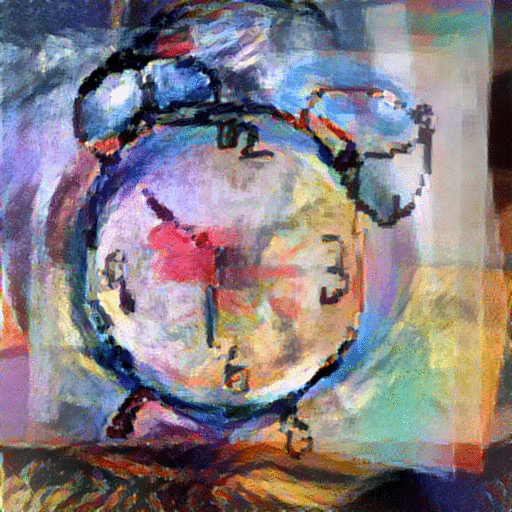 |
MRFs with Average Image: We repeated the same approach with using an average image with a sketch and its top k=5 retrieved images as the content input and a painting as the style input. The results are shown below:
|
|
 |
|
|
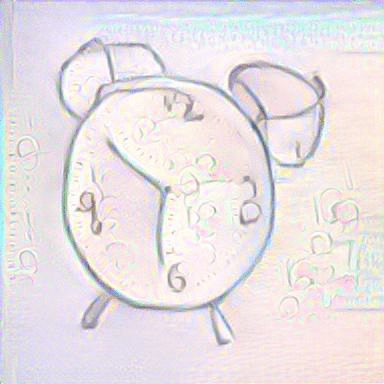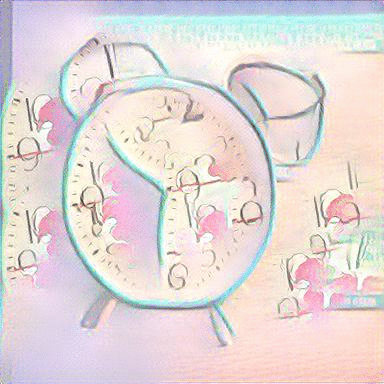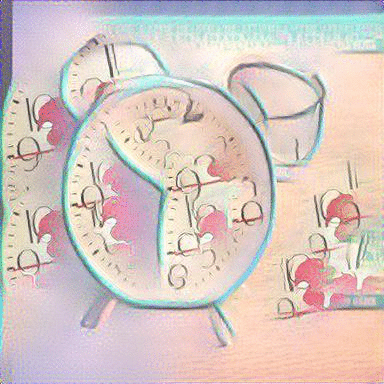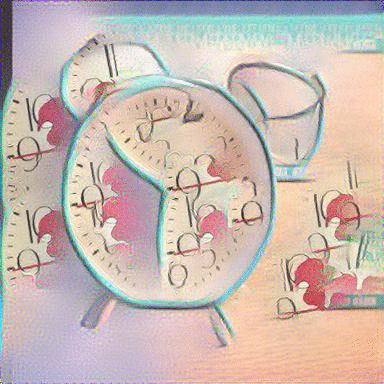 |
Limitations
In conclusion, the methods used were not effective in generating photorealistic images, but with the process of computing average images, we were able to produce interesting non-photorealistic artwork. This raises the question of an evaluation metric for these kinds of generative tasks. It is not as simple as deciding whether the resulting artwork looks "good" or "bad" due to the subjective nature, and the artwork cannot be quantified either. Also, we wanted to be able to create an application to allow users to draw a sketch, select a painting, and be given a generated painting. In this case, the average image process (e.g. image retrieval, edge detection, finding correspondences, warping, averaging) would be done in the background. However, even with the use of NVIDIA Titan X GPU, the total process would not be able to be done in real-time (we estimate it would take over an hour).
Citations
Canny, J. 1986. A Computation Approach to Edge Detection. Pattern Analysis and Machine Intelligence, IEEE Transactions on 6 (1986): 679-698.
Gatys, L. A., Ecker, A. S., and Bethge, M. 2015. A Neural Algorithm of Artistic Style. ArXiv preprint; http://arxiv.org/abs/1508.06576.
Li, C., and Wand, M. 2016. Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis. ArXiv preprint; http://arxiv.org/abs/1601.04589.
Radford, A., Metz, L., and Chintala, S. 2015. Unsupervised Represntation Learning with Deep Convolutional Generative Adversarial Networks. ArXiv preprint; http://arxiv.org/abs/1511.06434.
Sangkloy, P., Burnell, N., Ham, C., and Hays, J. 2016. The Sketchy Database: Learning to Retrieve Badly Drawn Bunnies. ACM Transactions on Graphics (SIGGRAPH 2016).
Simonyan, K., and Zisserman, A. 2014. Very Deep Convolutional Networks for Large-Scale Image Recognition. ArXiv preprint; http://arxiv.org/abs/1409.1556.
Zhou, T., Jae Lee, Y., Yu, S. X., and Efros, A. A. 2015. Flowweb: Joint Image Set Alignment by Weaving Consistent, Pixel-wise Correspondences.