[NEW] NovGrid: A Flexible Grid World for Evaluating Agent Response to Novelty
[Long Oral] AAAI 2022 Spring Symposium on Designing Artificial Intelligence for Open Worlds
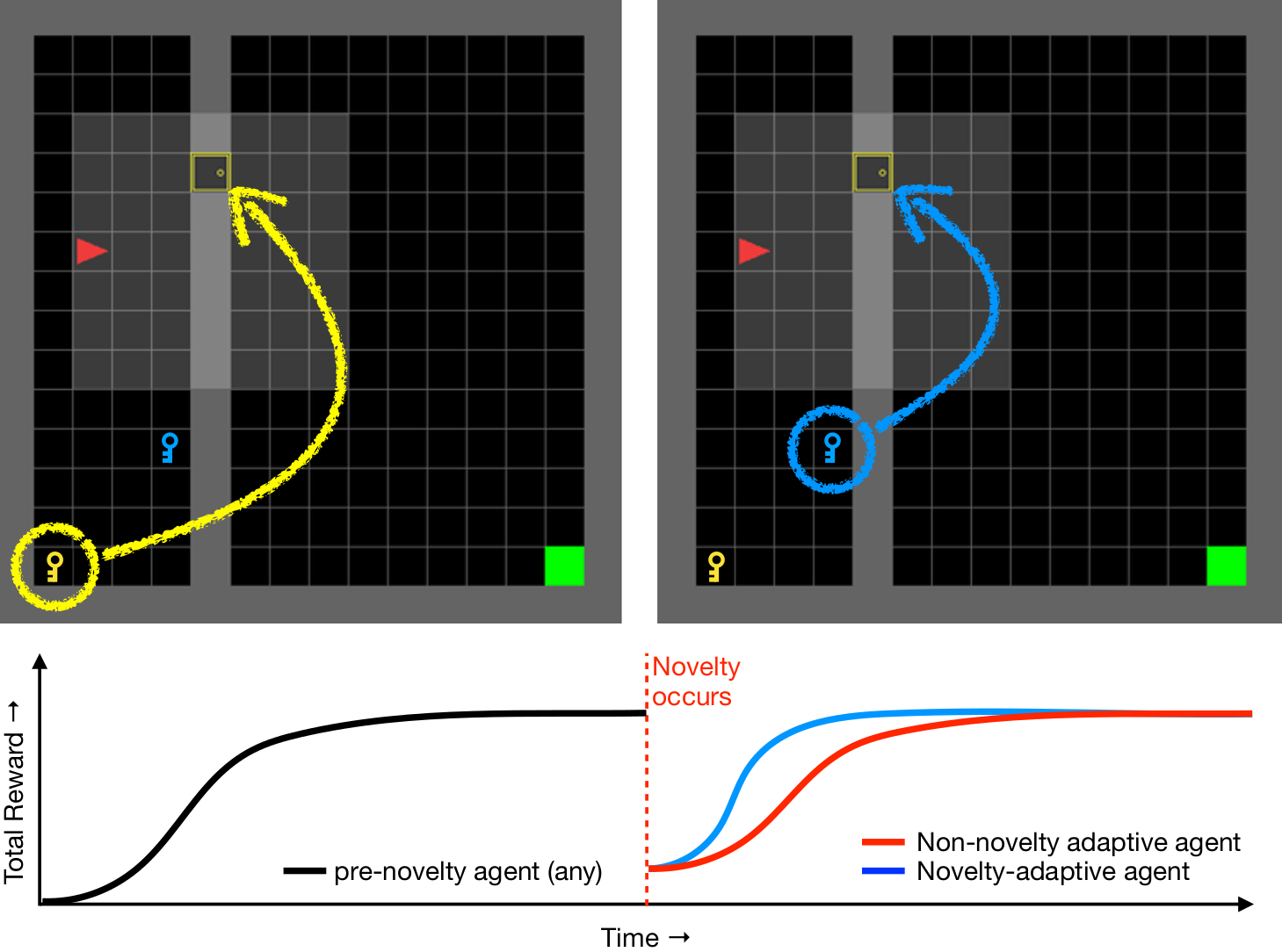
A robust body of reinforcement learning techniques have been developed to solve complex sequential decision making problems. However, these methods assume that train and evaluation tasks come from similarly or identically distributed environments. This assumption does not hold in real life where small novel changes to the environment can make a previously learned policy fail or introduce simpler solutions that might never be found. To that end we explore the concept of {\em novelty}, defined in this work as the sudden change to the mechanics or properties of environment. We provide an ontology of for novelties most relevant to sequential decision making, which distinguishes between novelties that affect objects versus actions, unary properties versus non-unary relations, and the distribution of solutions to a task. We introduce NovGrid, a novelty generation framework built on MiniGrid, acting as a toolkit for rapidly developing and evaluating novelty-adaptation-enabled reinforcement learning techniques. Along with the core NovGrid we provide exemplar novelties aligned with our ontology and instantiate them as novelty templates that can be applied to many MiniGrid-compliant environments. Finally, we present a set of metrics built into our framework for the evaluation of novelty-adaptation-enabled machine-learning techniques, and show characteristics of a baseline RL model using these metrics.