
Breakthrough Scaling Approach Cuts Cost, Improves Accuracy of Training DNN Models
A new machine-learning (ML) framework for clients with varied computing resources is the first of its kind to successfully scale deep neural network (DNN) models like those used to detect and recognize objects in still and video images.
The ability to uniformly scale the width (number of neurons) and depth (number of neural layers) of a DNN model means that remote clients can equitably participate in distributed, real-time training regardless of their computing resources. Resulting benefits include improved accuracy, increased efficiency, and reduced computational costs.
Developed by Georgia Tech researchers, the ScaleFL framework advances federated learning (FL), which is an ML approach inspired by the personal data scandals of the past decade.
Federated learning, a term coined by Google in 2016, enables a DNN model to be trained across decentralized devices or servers. Because data aren’t centralized with this approach, threats to data privacy and security are minimized.
The FL process begins with sending the initial parameters of a global DNN model to smartphones, IoT devices, edge servers, or other participating devices. These edge clients train their local version of the model using their unique data. All local results are aggregated and used to update the global model.
The process is repeated until the new model is fully trained and meets its design specifications.
Federated learning works best when remote clients training a new DNN model have comparable computational capabilities. But training can bog down if some participating remote-client devices have limited or fluctuating computing resources.
“In most real-life applications, computational resources differ significantly across clients. This heterogeneity prevents clients with insufficient resources from participating in certain FL tasks that require large models,” said School of Computer Science (CS) Ph.D. student Fatih Ilhan.
“Federated learning should promote equitable AI practices by supporting a resource-adaptive learning framework that can scale to heterogeneous clients with limited capacity,” said Ilhan, who is advised by Professor Ling Liu.
Ilhan is the lead author of ScaleFL: Resource-Adaptive Federated Learning with Heterogeneous Clients, which has been accepted by the 2023 Conference on Computer Vision and Pattern Recognition. CVPR 23 is set for June 18-22 in Vancouver, Canada.
Creating a framework that can adaptively scale the global DNN model based on a remote client’s computing resources is no easy feat. Ilhan says the balance between a model’s basic and complex feature extraction capabilities can be easily thrown out of whack when manipulating the number of neurons or the number of neuron layers of a DNN model.
“Since a deeper model is more capable of extracting higher order, complex features while a wider model has access to a finer resolution of lower-order, basic features, performing model size reduction across one dimension causes unbalance in terms of the learning capabilities of the resulting model,” said Ilhan.
The team overcomes these challenges, in part, by incorporating early exit classifiers into ScaleFL.
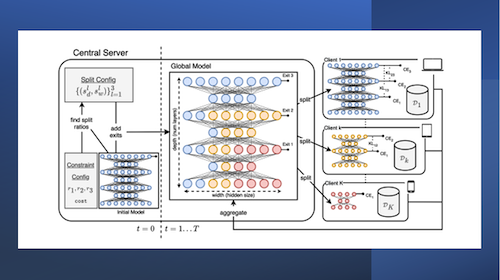
These ML-based tools are designed to optimize accuracy and efficiency by introducing intermediate decision points in the classification process. This capability enables a model to complete an inference task as soon as it is confident in its prediction without processing the whole model.
“ScaleFL injects these classifiers to the global model at certain layers based on the model architecture and computational constraints at each complexity level. This enables forming low-cost local models by keeping the layers up to the corresponding exit,” said Ilhan.
“Two-dimensional scaling with splitting the model along depth and width dimensions yields uniformly scaled, efficient local models for resource-constrained clients. As a result, the global model performs better when compared to baseline FL approaches and existing algorithms. Local models at different complexity levels also perform significantly better for clients that are resource-constrained at inference time.”
The exit classifiers that help balance a model’s basic and complex features also play into the second part of ScaleFL’s secret sauce, self-distillation.
Self-distillation is a form of knowledge sharing that transfers knowledge from a ‘teacher’ model to a smaller ‘student’ model. ScaleFL applies this process within the same network. It compares early predictions made by the exit classifiers (students) with the final predictions of the teacher for local models during optimization. This technique prevents isolation and improves the knowledge transfer among subnetworks of different levels in ScaleFL.
Ilhan and his collaborators extensively tested ScaleFL on three image classification datasets and two natural language processing datasets.
“Our experiments show that ScaleFL outperforms existing representative heterogeneous federated learning approaches. In local model evaluations, we were able to reduce latency by two times and the model size by four times, all while keeping the performance loss below 2%,” said Ilhan.


